
Gordon Forbes
@gforb.bsky.social
98 followers
100 following
55 posts
I love Netflix for their data science blog and The BBC for their ggplot2 resources.
Posts
Media
Videos
Starter Packs

Gordon Forbes
@gforb.bsky.social
· Jul 30
Gordon Forbes
@gforb.bsky.social
· Jul 8
Reposted by Gordon Forbes

Giles
@gdeejay.bsky.social
· Jul 1





Reposted by Gordon Forbes



Reposted by Gordon Forbes

Gordon Forbes
@gforb.bsky.social
· Mar 28
Reposted by Gordon Forbes



Reposted by Gordon Forbes

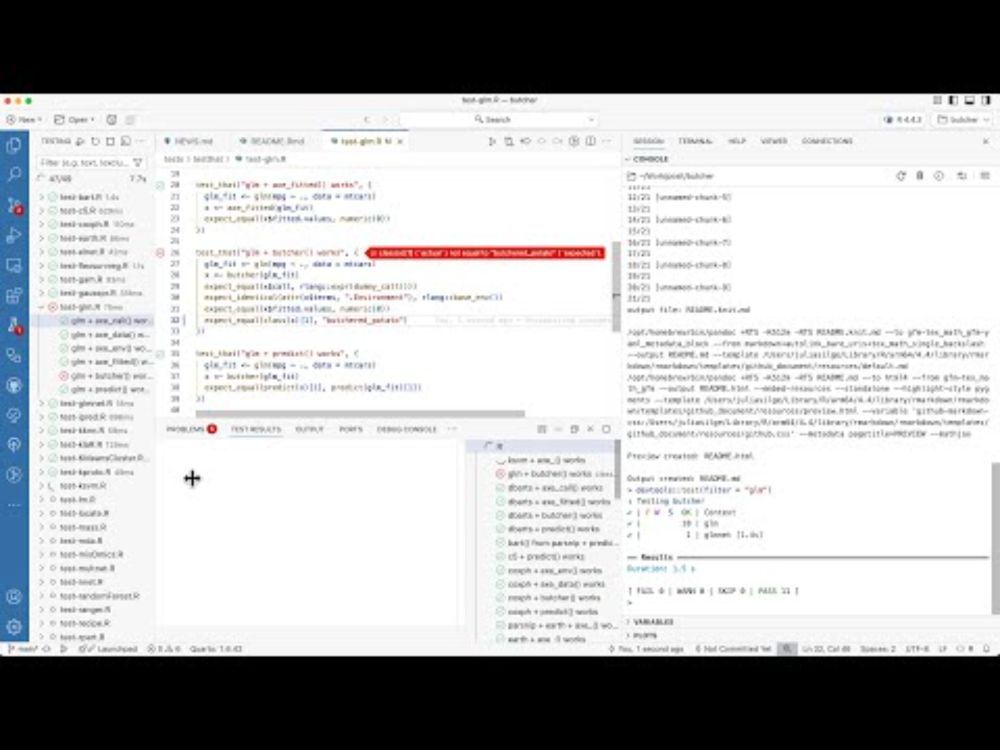
Reposted by Gordon Forbes

Gordon Forbes
@gforb.bsky.social
· Mar 13



Reposted by Gordon Forbes
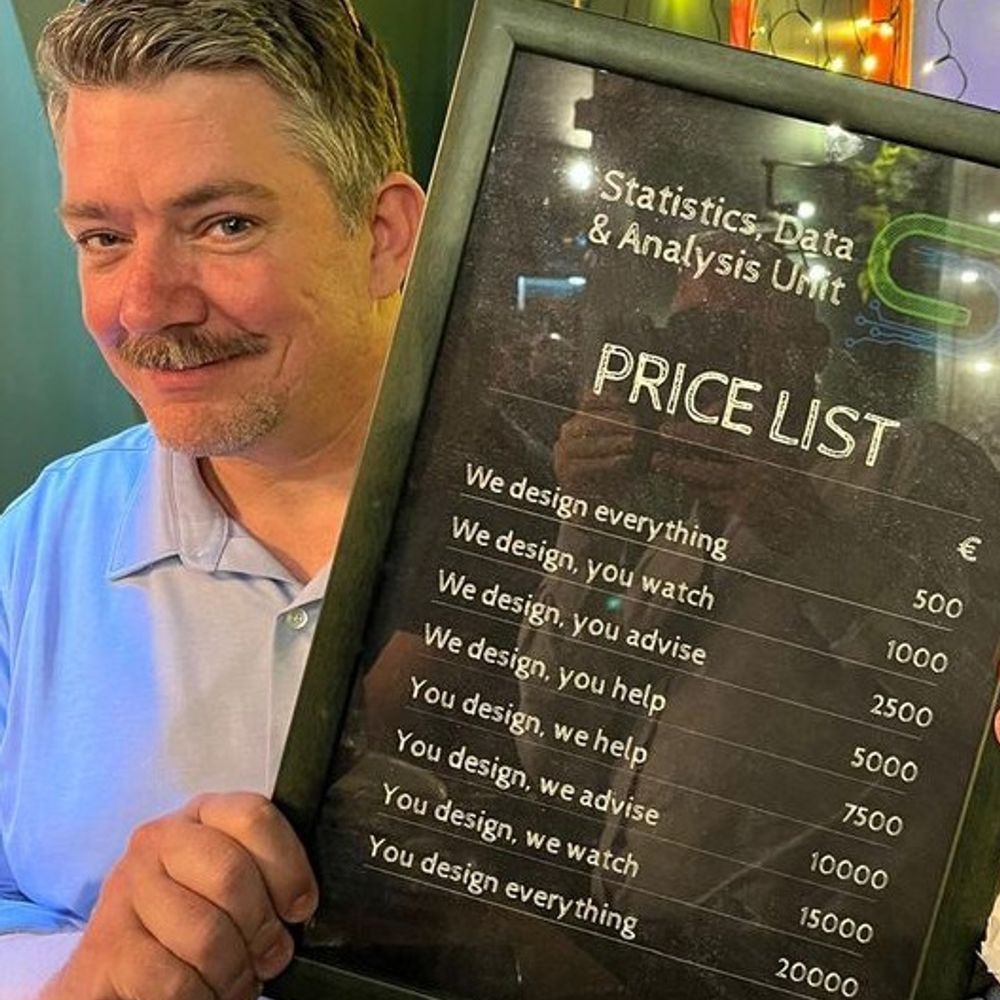
Darren Dahly
@statsepi.bsky.social
· Mar 12
Gordon Forbes
@gforb.bsky.social
· Mar 11
Gordon Forbes
@gforb.bsky.social
· Mar 7
Reposted by Gordon Forbes

Gordon Forbes
@gforb.bsky.social
· Mar 6
Gordon Forbes
@gforb.bsky.social
· Mar 5

Regression modelling strategies for improved prognostic prediction
Regression models such as the Cox proportional hazards model have had increasing use in modelling and estimating the prognosis of patients with a variety of diseases. Many applications involve a larg...
onlinelibrary.wiley.com
Reposted by Gordon Forbes

Tim Morris
@timpmorris.bsky.social
· Feb 28
Reposted by Gordon Forbes

Hadley Wickham
@hadley.nz
· Feb 27

