



Joe Janizek
@joejanizek.bsky.social
physician-scientist, interested in AI safety/interpretability in biology/medicine. jjanizek.github.io
Reposted by Joe Janizek

Thrilled to share that @ethanweinberger.bsky.social is becoming Dr. Weinberger in CSE2, where he is presenting his work, including the popular contrastiveVI for single-cell data (Weinberger et al. Nature Methods)! I feel so fortunate to work with such amazing Ph.D. students at @uwcse.bsky.social! 🎉🎓



April 22, 2025 at 2:49 AM
Thrilled to share that @ethanweinberger.bsky.social is becoming Dr. Weinberger in CSE2, where he is presenting his work, including the popular contrastiveVI for single-cell data (Weinberger et al. Nature Methods)! I feel so fortunate to work with such amazing Ph.D. students at @uwcse.bsky.social! 🎉🎓
Reposted by Joe Janizek

Medical education 🌶️🔥take: the threat of cognitive deskilling from genAI technologies is the #1 things medical educators need to be talking about right now.
March 7, 2025 at 1:49 PM
Medical education 🌶️🔥take: the threat of cognitive deskilling from genAI technologies is the #1 things medical educators need to be talking about right now.
Reposted by Joe Janizek

AI deployments in health are often understudied because they require time and careful analysis.⌛️🤔
We share thoughts in @ai.nejm.org about a recent AI tool for emergency dept triage that: 1) improves wait times and fairness (!), and 2) helps nurses unevenly based on triage ability
We share thoughts in @ai.nejm.org about a recent AI tool for emergency dept triage that: 1) improves wait times and fairness (!), and 2) helps nurses unevenly based on triage ability

February 27, 2025 at 9:06 PM
AI deployments in health are often understudied because they require time and careful analysis.⌛️🤔
We share thoughts in @ai.nejm.org about a recent AI tool for emergency dept triage that: 1) improves wait times and fairness (!), and 2) helps nurses unevenly based on triage ability
We share thoughts in @ai.nejm.org about a recent AI tool for emergency dept triage that: 1) improves wait times and fairness (!), and 2) helps nurses unevenly based on triage ability
The Gumbel-softmax distribution
Not discrete, not continuous, but a secret third thing
February 21, 2025 at 1:11 AM
The Gumbel-softmax distribution
Reposted by Joe Janizek

I've been developing a semantic search tool that covers not just bioRxiv and medRxiv, but the entire PubMed database. This means you can search across a massive collection of biomedical research using keywords, questions, hypotheses, or even full abstracts. Try it out: mssearch.xyz
Streamlit
mssearch.xyz
February 16, 2025 at 7:02 PM
I've been developing a semantic search tool that covers not just bioRxiv and medRxiv, but the entire PubMed database. This means you can search across a massive collection of biomedical research using keywords, questions, hypotheses, or even full abstracts. Try it out: mssearch.xyz
Reposted by Joe Janizek

What should we teach our undergrads about machine learning? I wrote up some ideas for restructuring Machine Learning 101.

Machine Learning 101?
Imagining a new syllabus for a first course on machine learning.
www.argmin.net
February 13, 2025 at 3:39 PM
What should we teach our undergrads about machine learning? I wrote up some ideas for restructuring Machine Learning 101.
Think how much performance we might be leaving on the table by not training classifiers on increasingly invasive biometrics. Pictured: medium-term radiologist-AI centaur-configuration possibility

February 11, 2025 at 11:55 PM
Think how much performance we might be leaving on the table by not training classifiers on increasingly invasive biometrics. Pictured: medium-term radiologist-AI centaur-configuration possibility
If this was an AI paper, you’d brand it as an interpretability technique that discovers a latent “node detection” circuit in the neural network
pubs.rsna.org/doi/10.1148/...
pubs.rsna.org/doi/10.1148/...


February 11, 2025 at 11:40 PM
If this was an AI paper, you’d brand it as an interpretability technique that discovers a latent “node detection” circuit in the neural network
pubs.rsna.org/doi/10.1148/...
pubs.rsna.org/doi/10.1148/...
Reposted by Joe Janizek
There is a lot of buzz about our new paper in Nature Medicine on the effects of LLMs (GPT-4) on physician management reasoning! I had TONS of fun working on this -- but what it MEANS requires some unpacking.
A 🧵⬇️
bsky.app/profile/ucsf...
A 🧵⬇️
bsky.app/profile/ucsf...

A new study in @natmedicine.bsky.social finds GPT-4 can enhance physicians’ clinical decision-making, improving open-ended management reasoning. While promising, experts stress the need for human oversight to mitigate risks like AI bias and over-reliance.
Read more: www.nature.com/articles/s41...
Read more: www.nature.com/articles/s41...

February 8, 2025 at 1:37 PM
There is a lot of buzz about our new paper in Nature Medicine on the effects of LLMs (GPT-4) on physician management reasoning! I had TONS of fun working on this -- but what it MEANS requires some unpacking.
A 🧵⬇️
bsky.app/profile/ucsf...
A 🧵⬇️
bsky.app/profile/ucsf...
Reposted by Joe Janizek

Insanely good news if this holds up.
Brainwide silencing of prion protein by AAV-mediated delivery of an engineered compact epigenetic editor
www.science.org/doi/10.1126/...
Brainwide silencing of prion protein by AAV-mediated delivery of an engineered compact epigenetic editor
www.science.org/doi/10.1126/...
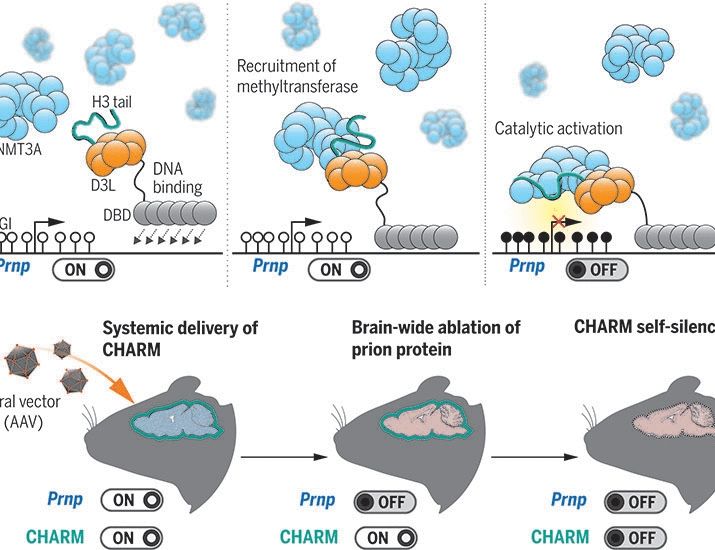
Brainwide silencing of prion protein by AAV-mediated delivery of an engineered compact epigenetic editor
Prion disease is caused by misfolding of the prion protein (PrP) into pathogenic self-propagating conformations, leading to rapid-onset dementia and death. However, elimination of endogenous PrP halts...
www.science.org
February 5, 2025 at 4:12 AM
Insanely good news if this holds up.
Brainwide silencing of prion protein by AAV-mediated delivery of an engineered compact epigenetic editor
www.science.org/doi/10.1126/...
Brainwide silencing of prion protein by AAV-mediated delivery of an engineered compact epigenetic editor
www.science.org/doi/10.1126/...
Reposted by Joe Janizek

A long post about what’s happening to the science funding agencies in the US and why. As mentioned, this one just kept getting longer even as I kept stripping curse words from it.
www.science.org/content/blog...
www.science.org/content/blog...

What's Happening Inside the NIH and NSF
www.science.org
February 4, 2025 at 4:40 PM
A long post about what’s happening to the science funding agencies in the US and why. As mentioned, this one just kept getting longer even as I kept stripping curse words from it.
www.science.org/content/blog...
www.science.org/content/blog...
Reposted by Joe Janizek

New (short) paper showing how the in-context inductive biases of vision-language models — the way that they generalize concepts learned in context — depend on the modality and phrasing! arxiv.org/abs/2502.01530 Quick summary: 1/5

The in-context inductive biases of vision-language models differ across modalities
Inductive biases are what allow learners to make guesses in the absence of conclusive evidence. These biases have often been studied in cognitive science using concepts or categories -- e.g. by testin...
arxiv.org
February 4, 2025 at 4:53 PM
New (short) paper showing how the in-context inductive biases of vision-language models — the way that they generalize concepts learned in context — depend on the modality and phrasing! arxiv.org/abs/2502.01530 Quick summary: 1/5
Reposted by Joe Janizek

i use claude as a rubber duck a lot, and i always make sure to thank it. not because i think that it can appreciate my thanks but i refuse to surround myself with objects which i experience as human but refuse to treat as human. we should not be learning to dehumanize the experience of intelligence.

Just took my first Waymo and definitely said “Thank you” as I left, before I could stop myself.
February 4, 2025 at 7:09 AM
i use claude as a rubber duck a lot, and i always make sure to thank it. not because i think that it can appreciate my thanks but i refuse to surround myself with objects which i experience as human but refuse to treat as human. we should not be learning to dehumanize the experience of intelligence.
Reposted by Joe Janizek

📈How far are leading models from mastering realistic medical tasks? MedXpertQA, our new text & multimodal medical benchmark, reveals gaps in model abilities
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
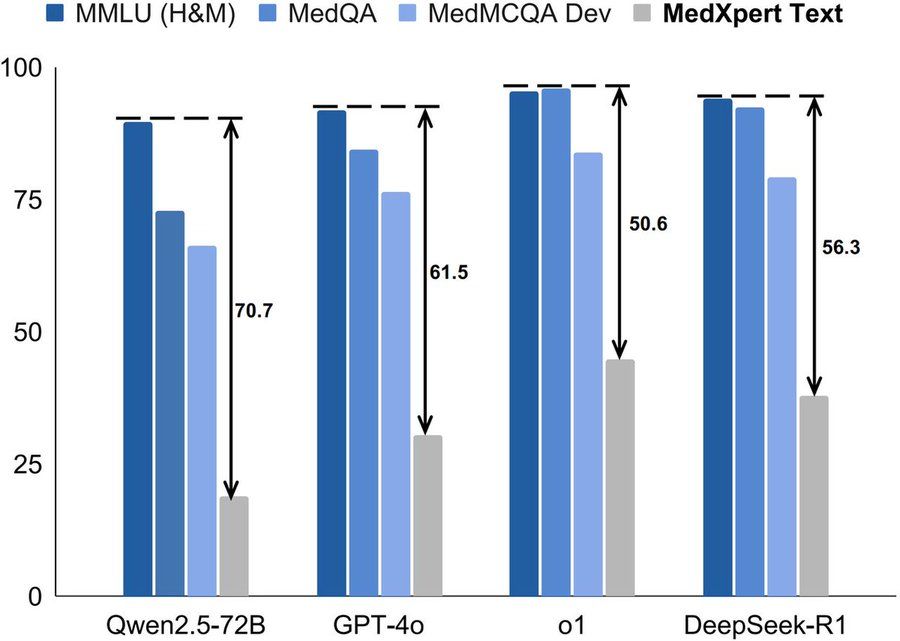
February 4, 2025 at 1:29 PM
📈How far are leading models from mastering realistic medical tasks? MedXpertQA, our new text & multimodal medical benchmark, reveals gaps in model abilities
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
Business idea: Anki decks but for Involuntary Memory
February 4, 2025 at 6:04 AM
Business idea: Anki decks but for Involuntary Memory
Reposted by Joe Janizek




Reposted by Joe Janizek

“An AI escaped from the lab!”
“Which one?”
“Uh, something named helpful-only”
“Dear god…”
“Which one?”
“Uh, something named helpful-only”
“Dear god…”

February 3, 2025 at 6:00 PM
“An AI escaped from the lab!”
“Which one?”
“Uh, something named helpful-only”
“Dear god…”
“Which one?”
“Uh, something named helpful-only”
“Dear god…”
Concretely, you can do a back of the envelope calculation on how much it would have cost to generate expert reasoning traces for their dataset — they initially did 59K questions, which for this difficulty level would take experts greater than 30 min per question (see GPQA paper)
This sort of thing should make you update your floor on how much progress we’ll get in “AI” more broadly — in the most pessimistic scenarios w.r.t. progress, the ease of creating interesting/meaningful datasets is going to continue to get so much easier
February 3, 2025 at 4:48 PM
Concretely, you can do a back of the envelope calculation on how much it would have cost to generate expert reasoning traces for their dataset — they initially did 59K questions, which for this difficulty level would take experts greater than 30 min per question (see GPQA paper)
Reposted by Joe Janizek

« appending "Wait" multiple times to the model's generation » is our current most likely path to AGI :)
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.

February 3, 2025 at 2:31 PM
« appending "Wait" multiple times to the model's generation » is our current most likely path to AGI :)
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.
One of the most remarkable parts of the s1 paper, IMO, is how much AI progress drives further AI progress. For s1, authors needed reasoning traces for SFT — these were generated with Gemini. The questions those reasoning traces were generated for needed to be difficult — so they measured ..




February 3, 2025 at 4:12 PM
One of the most remarkable parts of the s1 paper, IMO, is how much AI progress drives further AI progress. For s1, authors needed reasoning traces for SFT — these were generated with Gemini. The questions those reasoning traces were generated for needed to be difficult — so they measured ..
Posting your GitHub contributions is passé — in 2025 I want to see your Anki review calendar


February 1, 2025 at 5:14 PM
Posting your GitHub contributions is passé — in 2025 I want to see your Anki review calendar
Reposted by Joe Janizek
Overfitting, as it is colloquially described in data science and machine learning, doesn’t exist. www.argmin.net/p/thou-shalt...

Thou Shalt Not Overfit
Venting my spleen about the persistent inanity about overfitting.
www.argmin.net
January 30, 2025 at 3:35 PM
Overfitting, as it is colloquially described in data science and machine learning, doesn’t exist. www.argmin.net/p/thou-shalt...
Reading about "majority label bias" in prompting/ICL (see arxiv.org/pdf/2102.09690, arxiv.org/pdf/2312.16549). It seems like an interesting behavior, and not clearly "faulty" -- i.e. calibrating the output of the model to the base rate frequency of the label in your prompt?

January 29, 2025 at 7:49 PM
Reading about "majority label bias" in prompting/ICL (see arxiv.org/pdf/2102.09690, arxiv.org/pdf/2312.16549). It seems like an interesting behavior, and not clearly "faulty" -- i.e. calibrating the output of the model to the base rate frequency of the label in your prompt?
the best part of a dedicated research month is getting to spend time reading and running experiments again, but a close runner up is getting to see the light of day in the winter


January 25, 2025 at 11:23 PM
the best part of a dedicated research month is getting to spend time reading and running experiments again, but a close runner up is getting to see the light of day in the winter
Want to start compiling a list of all open-source (or at least open-weight) multimodal models that can accept multiple interleaved images/text as input. OpenFlamingo, LLaVA OneVision… others?
January 25, 2025 at 6:43 PM
Want to start compiling a list of all open-source (or at least open-weight) multimodal models that can accept multiple interleaved images/text as input. OpenFlamingo, LLaVA OneVision… others?