
Mohit Bansal
@mohitbansal.bsky.social
1.3K followers
190 following
35 posts
Parker Distinguished Professor, @UNC. Program Chair #EMNLP2024. Director http://MURGeLab.cs.unc.edu (@uncnlp). @Berkeley_AI @TTIC_Connect @IITKanpur
#NLP #CV #AI #ML
https://www.cs.unc.edu/~mbansal/
Posts
Media
Videos
Starter Packs
Pinned

Mohit Bansal
@mohitbansal.bsky.social
· Jan 21


Mohit Bansal
@mohitbansal.bsky.social
· Jul 15
Reposted by Mohit Bansal

Peter Hase
@peterbhase.bsky.social
· Jul 14
Reposted by Mohit Bansal


Reposted by Mohit Bansal


Mohit Bansal
@mohitbansal.bsky.social
· May 21



Reposted by Mohit Bansal


Mohit Bansal
@mohitbansal.bsky.social
· May 6
Mohit Bansal
@mohitbansal.bsky.social
· May 5

Reposted by Mohit Bansal

Elias Stengel-Eskin
@esteng.bsky.social
· Apr 30

Reposted by Mohit Bansal

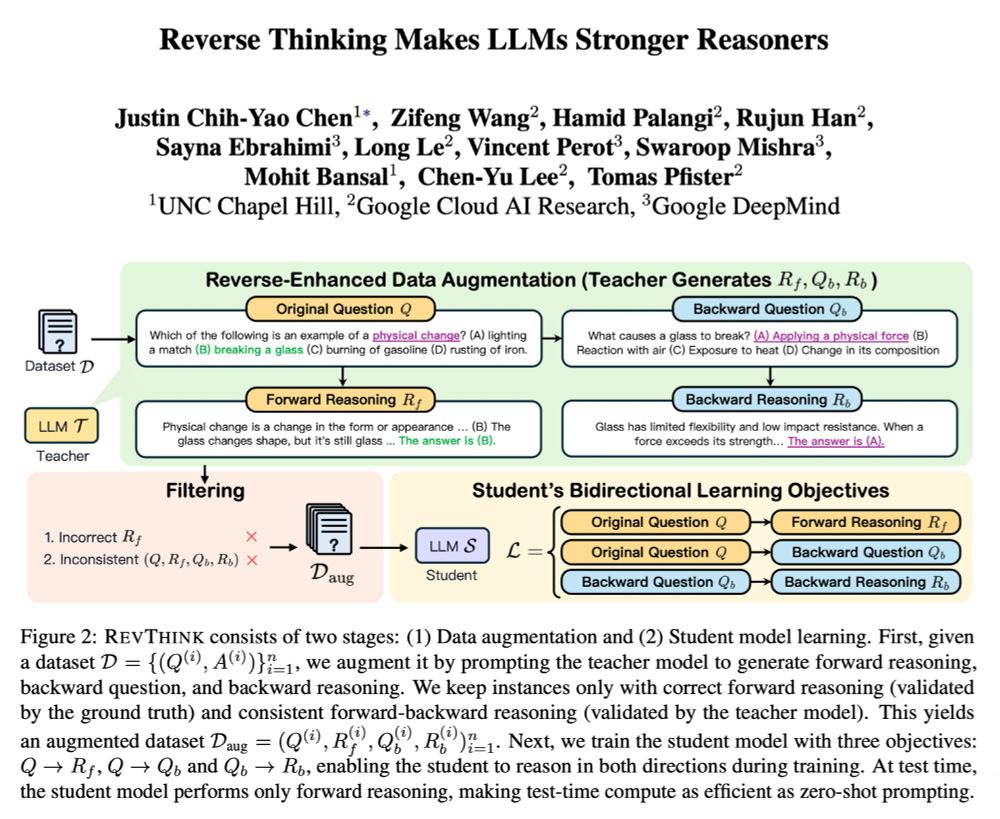
Reposted by Mohit Bansal
Elias Stengel-Eskin
@esteng.bsky.social
· Apr 29
Reposted by Mohit Bansal
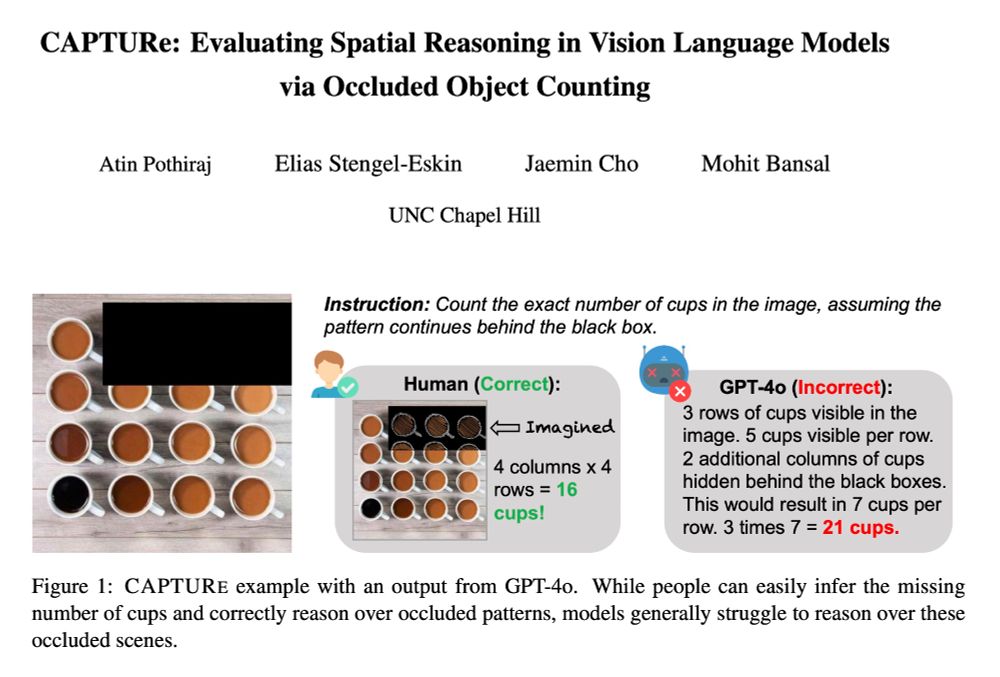

Reposted by Mohit Bansal

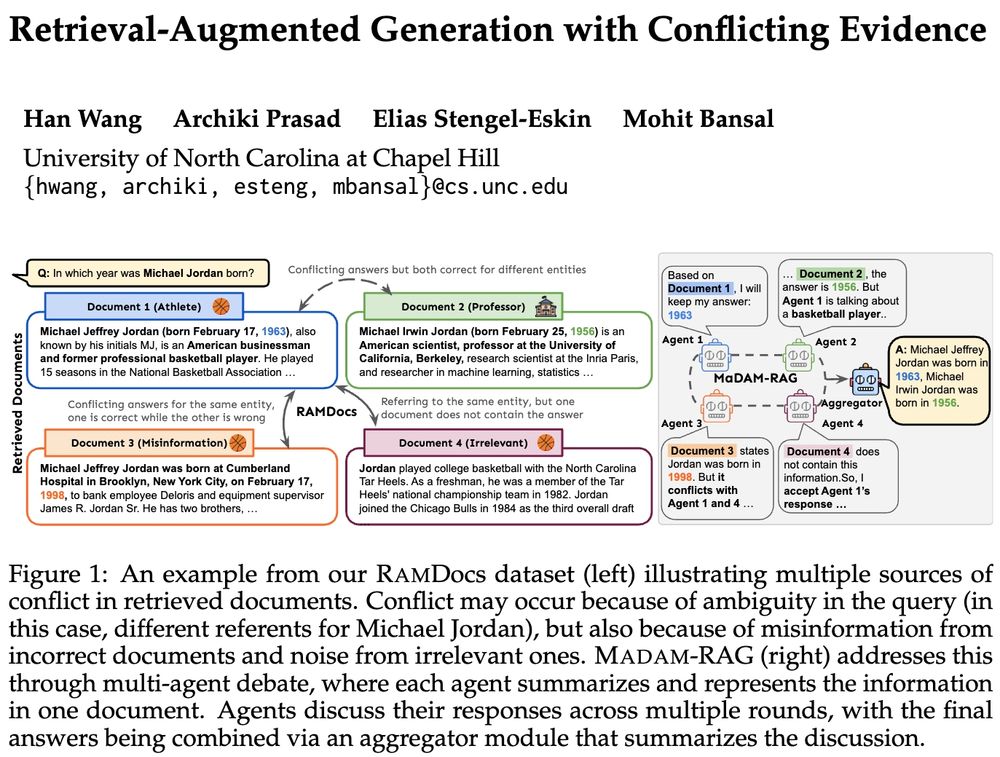
Reposted by Mohit Bansal

hanqix.bsky.social
@hanqix.bsky.social
· Apr 16
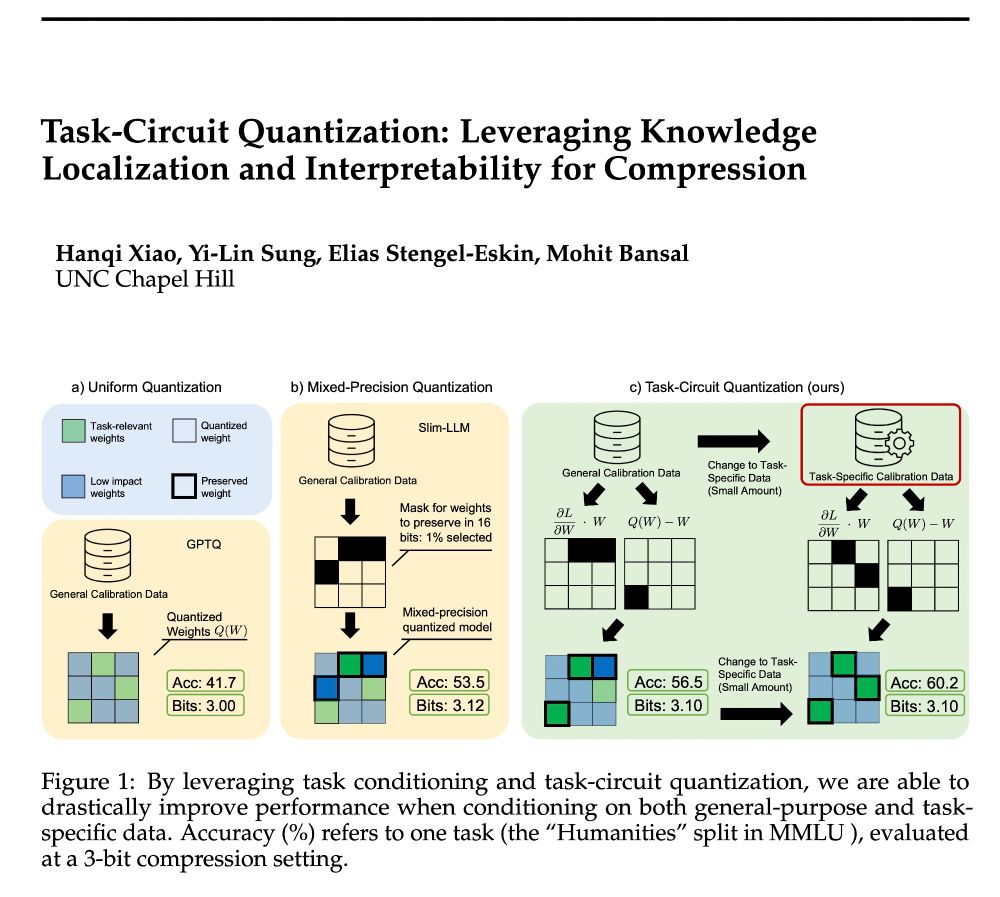
Reposted by Mohit Bansal

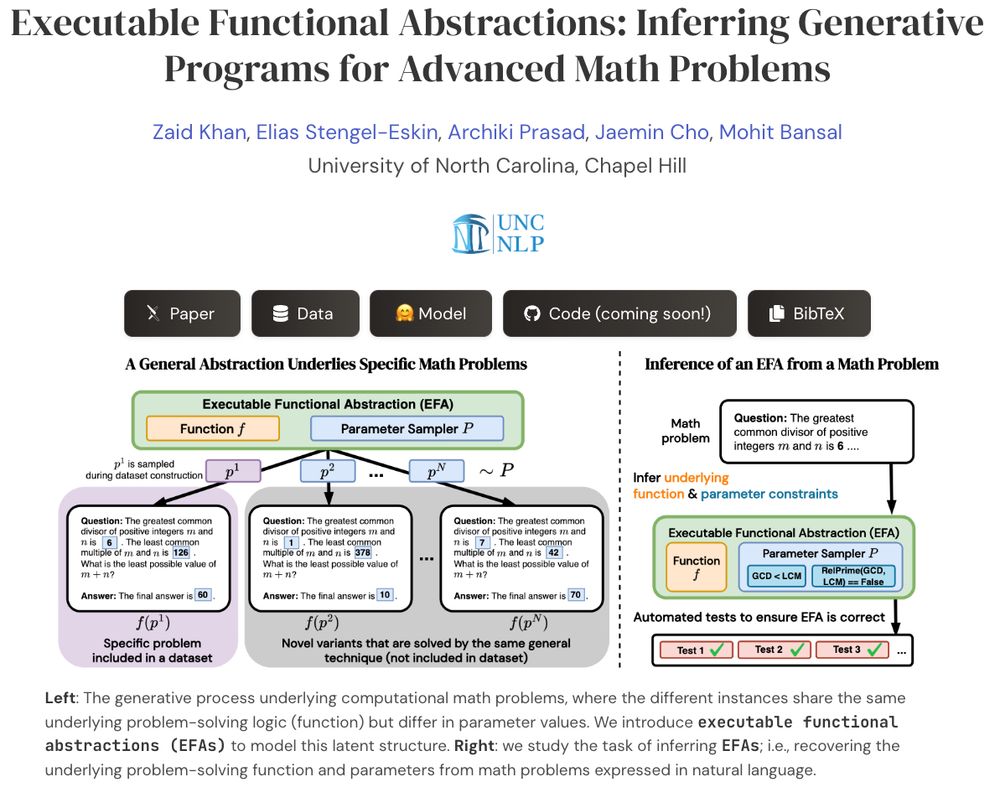
Reposted by Mohit Bansal
Reposted by Mohit Bansal



Reposted by Mohit Bansal





Reposted by Mohit Bansal
Elias Stengel-Eskin
@esteng.bsky.social
· Feb 25

Reposted by Mohit Bansal