




Nik Tzoumas
@niktz.bsky.social
Ophthalmologist & Welcome PhD Fellow ncl.ac.uk | Researching retinal disease w/ genetics & big data
Reposted by Nik Tzoumas

New post!
There was a lot of innovation in medicine and biomedical research this year, and I've tried to summarize the biggest ones in this blogpost.
Medical breakthroughs in 2025. Plus a serious note at the end.
www.scientificdiscovery.dev/p/medical-br...
There was a lot of innovation in medicine and biomedical research this year, and I've tried to summarize the biggest ones in this blogpost.
Medical breakthroughs in 2025. Plus a serious note at the end.
www.scientificdiscovery.dev/p/medical-br...

Medical breakthroughs in 2025
... and a happy new year.
www.scientificdiscovery.dev
December 28, 2025 at 6:37 PM
New post!
There was a lot of innovation in medicine and biomedical research this year, and I've tried to summarize the biggest ones in this blogpost.
Medical breakthroughs in 2025. Plus a serious note at the end.
www.scientificdiscovery.dev/p/medical-br...
There was a lot of innovation in medicine and biomedical research this year, and I've tried to summarize the biggest ones in this blogpost.
Medical breakthroughs in 2025. Plus a serious note at the end.
www.scientificdiscovery.dev/p/medical-br...
Reposted by Nik Tzoumas

#Statistics thought of the day: For longitudinal studies, don't treat the baseline measurement as the first follow-up measurement. Baseline cannot be considered a response to treatment. You'd be surprised how often this in done in #pharma. hbiostat.org/rmsc/long#mo... #StatsSky
7 Modeling Longitudinal Responses using Generalized Least Squares – Regression Modeling Strategies
hbiostat.org
December 22, 2025 at 1:45 PM
#Statistics thought of the day: For longitudinal studies, don't treat the baseline measurement as the first follow-up measurement. Baseline cannot be considered a response to treatment. You'd be surprised how often this in done in #pharma. hbiostat.org/rmsc/long#mo... #StatsSky
Reposted by Nik Tzoumas

is there a good citation discussing recent Gelman/Vehtari/etc style choices of prior? like what's on the Stan wiki but in the form of an academic paper? github.com/stan-dev/sta...

Prior Choice Recommendations
Stan development repository. The master branch contains the current release. The develop branch contains the latest stable development. See the Developer Process Wiki for details. - stan-dev/stan
github.com
December 22, 2025 at 12:22 AM
is there a good citation discussing recent Gelman/Vehtari/etc style choices of prior? like what's on the Stan wiki but in the form of an academic paper? github.com/stan-dev/sta...
Reposted by Nik Tzoumas

Our guidance regarding performance measures for medical AI models is finally out!
- Stop bashing AUROC, although it does not settle things
- Calibration and clinical utility are key
- Show risk distributions
- Classification statistics (e.g. F1) are improper
www.thelancet.com/journals/lan...
- Stop bashing AUROC, although it does not settle things
- Calibration and clinical utility are key
- Show risk distributions
- Classification statistics (e.g. F1) are improper
www.thelancet.com/journals/lan...

Evaluation of performance measures in predictive artificial intelligence models to support medical decisions: overview and guidance
Numerous measures have been proposed to illustrate the performance of predictive artificial
intelligence (AI) models. Selecting appropriate performance measures is essential
for predictive AI models i...
www.thelancet.com
December 13, 2025 at 2:04 PM
Our guidance regarding performance measures for medical AI models is finally out!
- Stop bashing AUROC, although it does not settle things
- Calibration and clinical utility are key
- Show risk distributions
- Classification statistics (e.g. F1) are improper
www.thelancet.com/journals/lan...
- Stop bashing AUROC, although it does not settle things
- Calibration and clinical utility are key
- Show risk distributions
- Classification statistics (e.g. F1) are improper
www.thelancet.com/journals/lan...
Reposted by Nik Tzoumas

Our latest preprint revisits the classic model of mutation-selection balance.
Do human recessive genes fit Haldane's 100-year old model?
This work is by the wonderful @jonj-udd.bsky.social, and co-mentored by @jeffspence.github.io
www.biorxiv.org/content/10.6...
Do human recessive genes fit Haldane's 100-year old model?
This work is by the wonderful @jonj-udd.bsky.social, and co-mentored by @jeffspence.github.io
www.biorxiv.org/content/10.6...

Allele Frequencies at Recessive Disease Genes are Mainly Determined by Pleiotropic Effects in Heterozygotes
The classic theory of mutation-selection balance predicts the equilibrium frequency of genetic variation under negative selection. The model predicts a simple relationship between the total frequency ...
www.biorxiv.org
December 13, 2025 at 4:45 PM
Our latest preprint revisits the classic model of mutation-selection balance.
Do human recessive genes fit Haldane's 100-year old model?
This work is by the wonderful @jonj-udd.bsky.social, and co-mentored by @jeffspence.github.io
www.biorxiv.org/content/10.6...
Do human recessive genes fit Haldane's 100-year old model?
This work is by the wonderful @jonj-udd.bsky.social, and co-mentored by @jeffspence.github.io
www.biorxiv.org/content/10.6...
Reposted by Nik Tzoumas

Another day, and another reference to these bangers. Contemporary causal inference has fundamentally changed the way I think about control variables and mediation analyses. These can show you why:
doi.org/10.1177/2515...
doi.org/10.1111/spc3...
doi.org/10.1177/2515...
doi.org/10.1177/2515...
doi.org/10.1111/spc3...
doi.org/10.1177/2515...
Sage Journals: Discover world-class research
Subscription and open access journals from Sage, the world's leading independent academic publisher.
doi.org
December 12, 2025 at 9:19 PM
Another day, and another reference to these bangers. Contemporary causal inference has fundamentally changed the way I think about control variables and mediation analyses. These can show you why:
doi.org/10.1177/2515...
doi.org/10.1111/spc3...
doi.org/10.1177/2515...
doi.org/10.1177/2515...
doi.org/10.1111/spc3...
doi.org/10.1177/2515...

Reposted by Nik Tzoumas

I maintain that this is an excellent benchmark for d-type effect sizes:
Sleep satisfaction & duration declined with childbirth & reached a nadir during the first 3 months postpartum, with women more strongly affected (satisfaction d = -0.79, duration minus 62 min, d = -0.90)>
Sleep satisfaction & duration declined with childbirth & reached a nadir during the first 3 months postpartum, with women more strongly affected (satisfaction d = -0.79, duration minus 62 min, d = -0.90)>

Long-term effects of pregnancy and childbirth on sleep satisfaction and duration of first-time and experienced mothers and fathers
AbstractStudy Objectives. To examine the changes in mothers’ and fathers’ sleep satisfaction and sleep duration across prepregnancy, pregnancy, and the pos
academic.oup.com
December 9, 2025 at 9:50 AM
I maintain that this is an excellent benchmark for d-type effect sizes:
Sleep satisfaction & duration declined with childbirth & reached a nadir during the first 3 months postpartum, with women more strongly affected (satisfaction d = -0.79, duration minus 62 min, d = -0.90)>
Sleep satisfaction & duration declined with childbirth & reached a nadir during the first 3 months postpartum, with women more strongly affected (satisfaction d = -0.79, duration minus 62 min, d = -0.90)>
Reposted by Nik Tzoumas
Big new blogpost!
My guide to data visualization, which includes a very long table of contents, tons of charts, and more.
--> Why data visualization matters and how to make charts more effective, clear, transparent, and sometimes, beautiful.
www.scientificdiscovery.dev/p/salonis-gu...
My guide to data visualization, which includes a very long table of contents, tons of charts, and more.
--> Why data visualization matters and how to make charts more effective, clear, transparent, and sometimes, beautiful.
www.scientificdiscovery.dev/p/salonis-gu...

December 9, 2025 at 8:28 PM
Big new blogpost!
My guide to data visualization, which includes a very long table of contents, tons of charts, and more.
--> Why data visualization matters and how to make charts more effective, clear, transparent, and sometimes, beautiful.
www.scientificdiscovery.dev/p/salonis-gu...
My guide to data visualization, which includes a very long table of contents, tons of charts, and more.
--> Why data visualization matters and how to make charts more effective, clear, transparent, and sometimes, beautiful.
www.scientificdiscovery.dev/p/salonis-gu...
Reposted by Nik Tzoumas
Excellent note @avehtari.bsky.social - with insights I had missed about how the effective posterior draw sample size depends on which part of the posterior distribution you are estimating for a parameter. #Statistics #StatsSky

I wrote more about how effective sample size depends on the quantity of interest statmodeling.stat.columbia.edu/2025/12/02/e...
Effective sample size depends on the quantity | Statistical Modeling, Causal Inference, and Social Science
statmodeling.stat.columbia.edu
December 2, 2025 at 1:38 PM
Excellent note @avehtari.bsky.social - with insights I had missed about how the effective posterior draw sample size depends on which part of the posterior distribution you are estimating for a parameter. #Statistics #StatsSky
Reposted by Nik Tzoumas

Here’s an example of one we did where working through the process made it clear that the data simply weren’t sufficient to answer the question of interest:
onlinelibrary.wiley.com/doi/abs/10.1...
onlinelibrary.wiley.com/doi/abs/10.1...
onlinelibrary.wiley.com
November 27, 2025 at 3:17 PM
Here’s an example of one we did where working through the process made it clear that the data simply weren’t sufficient to answer the question of interest:
onlinelibrary.wiley.com/doi/abs/10.1...
onlinelibrary.wiley.com/doi/abs/10.1...
Reposted by Nik Tzoumas

![Comic. Panels up to the 10-year point are grayed out. New panels since the Ten Years comic, which chronicles the first ten years of PERSON 1's journey with cancer: (1) [two people in bed] PERSON 1 (woman): One more chapter? PERSON 2 (man): Don’t we both have to get up early? PERSON 1: Nnnnnggggh PERSON 2: Sure, good point. (2) [many people wearing masks, walking while looking at graphs on their phones] (3) [birds landing on people] PERSON 2 in beanie and scarf: Hah! They like *my* seeds best. PERSON 1 in scarf holding phone with a bird sitting on it: Wait, how do I take a picture of this one? (4) [two people rowing boats with tree landscape] (5) [Person 1 carries overflowing stack of things to Person 2 in bed] PERSON 1: I brought you honey lemon tea, more pillows, a cinnamon roll, Tylenol, another blanket, a– PERSON 2: It was just Appendicitis, I’m really– PERSON 1: *It is my turn to take care of you and I am going to do it right!* (6) [Two people in car] (7) [still in car) PERSON 1: Oh my god. PERSON 2: Oh my god. (8) [car driving] PERSON 1: Pull over! PERSON 2: I am! (9) [both people get out of car] (10) [Large colored panel of aurora borealis over water with both people looking on] (11) [Person 1 sits against tree while Person 2 lies on the ground] PERSON 1: Fifteen years. No sign of the cancer. (12) I *am* having some weird symptoms. Joint pain. Fatigue. I think I’m losing my close-up vision. PERSON 2: Yeah. Me too. (13) PERSON 2: I think we’re getting old. (14) PERSON 1: I guess that’s okay. PERSON 2: It’s all I wanted.](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:cz73r7iyiqn26upot4jtjdhk/bafkreihwhjblp5lyiwp63ouar7ocfea7evmckytoeo7rkfuoo4gw5rnrra@jpeg)
November 26, 2025 at 10:32 PM
Reposted by Nik Tzoumas

My #rstats cheat code for today is the binom.confint function in the binom package that will spit out *12* different ways of calculating a CI for a proportion.
Also, this is why you use R for statistics...
(and of course the correct CI method is bayes 😎)
Also, this is why you use R for statistics...
(and of course the correct CI method is bayes 😎)

November 16, 2025 at 2:52 AM
My #rstats cheat code for today is the binom.confint function in the binom package that will spit out *12* different ways of calculating a CI for a proportion.
Also, this is why you use R for statistics...
(and of course the correct CI method is bayes 😎)
Also, this is why you use R for statistics...
(and of course the correct CI method is bayes 😎)
Reposted by Nik Tzoumas

Very useful table of insufficient examples vs. best-practices for statistical reporting!
Will definitely point some of my colleagues to it! 📈
Will definitely point some of my colleagues to it! 📈

November 15, 2025 at 8:49 AM
Very useful table of insufficient examples vs. best-practices for statistical reporting!
Will definitely point some of my colleagues to it! 📈
Will definitely point some of my colleagues to it! 📈
Reposted by Nik Tzoumas

I've done a lot of work in Python this fall, and it hasn't endeared me to the language at all. Why does stuff have to be so complicated when you're doing it in Python?
blog.genesmindsmachines.com/p/python-is-...
blog.genesmindsmachines.com/p/python-is-...
Python is not a great language for data science. Part 1: The experience
It may be a good language for data science, but it’s not a great one.
blog.genesmindsmachines.com
November 13, 2025 at 4:16 PM
I've done a lot of work in Python this fall, and it hasn't endeared me to the language at all. Why does stuff have to be so complicated when you're doing it in Python?
blog.genesmindsmachines.com/p/python-is-...
blog.genesmindsmachines.com/p/python-is-...
Reposted by Nik Tzoumas

First time on Bsky and first big announcement!
I am excited to announce that our new study explaining the missing heritability of many phenotypes using WGS data from ~347,000 UK Biobank participants has just been published in @Nature.
Our manuscript is here: www.nature.com/articles/s41....
I am excited to announce that our new study explaining the missing heritability of many phenotypes using WGS data from ~347,000 UK Biobank participants has just been published in @Nature.
Our manuscript is here: www.nature.com/articles/s41....

Estimation and mapping of the missing heritability of human phenotypes - Nature
WGS data were used from 347,630 individuals with European ancestry in the UK Biobank to obtain high-precision estimates of coding and non-coding rare variant heritability for 34 co...
www.nature.com
November 12, 2025 at 5:57 PM
First time on Bsky and first big announcement!
I am excited to announce that our new study explaining the missing heritability of many phenotypes using WGS data from ~347,000 UK Biobank participants has just been published in @Nature.
Our manuscript is here: www.nature.com/articles/s41....
I am excited to announce that our new study explaining the missing heritability of many phenotypes using WGS data from ~347,000 UK Biobank participants has just been published in @Nature.
Our manuscript is here: www.nature.com/articles/s41....
Reposted by Nik Tzoumas

This is important. People still do this a lot, and it ends up being a back-door method of inferring an interaction (e.g., “effect was significant in women but not men”)

“changes in statistical significance are often not themselves statistically significant. … even large changes in significance levels can correspond to small, nonsignificant changes in the underlying quantities.”
www.tandfonline.com/doi/abs/10.1...
#Statistics
www.tandfonline.com/doi/abs/10.1...
#Statistics

The Difference Between “Significant” and “Not Significant” is not Itself Statistically Significant
It is common to summarize statistical comparisons by declarations of statistical significance or nonsignificance. Here we discuss one problem with such declarations, namely that changes in statisti...
www.tandfonline.com
November 9, 2025 at 1:26 PM
This is important. People still do this a lot, and it ends up being a back-door method of inferring an interaction (e.g., “effect was significant in women but not men”)
Reposted by Nik Tzoumas
I just posted a critique of this paper at discourse.datamethods.org/t/critique-o... where I hope others will add their thoughts #StatsSky #EpiSky #Statistics #rct

November 9, 2025 at 3:56 PM
I just posted a critique of this paper at discourse.datamethods.org/t/critique-o... where I hope others will add their thoughts #StatsSky #EpiSky #Statistics #rct
Reposted by Nik Tzoumas

How do GWAS and rare variant burden tests rank gene signals?
In new work @nature.com with @hakha.bsky.social, @jkpritch.bsky.social, and our wonderful coauthors we find that the key factors are what we call Specificity, Length, and Luck!
🧬🧪🧵
www.nature.com/articles/s41...
In new work @nature.com with @hakha.bsky.social, @jkpritch.bsky.social, and our wonderful coauthors we find that the key factors are what we call Specificity, Length, and Luck!
🧬🧪🧵
www.nature.com/articles/s41...

Specificity, length and luck drive gene rankings in association studies - Nature
Genetic association tests prioritize candidate genes based on different criteria.
www.nature.com
November 7, 2025 at 12:05 AM
How do GWAS and rare variant burden tests rank gene signals?
In new work @nature.com with @hakha.bsky.social, @jkpritch.bsky.social, and our wonderful coauthors we find that the key factors are what we call Specificity, Length, and Luck!
🧬🧪🧵
www.nature.com/articles/s41...
In new work @nature.com with @hakha.bsky.social, @jkpritch.bsky.social, and our wonderful coauthors we find that the key factors are what we call Specificity, Length, and Luck!
🧬🧪🧵
www.nature.com/articles/s41...
Reposted by Nik Tzoumas

The rapid growth in Mendelian randomization studies. Gibran Hemani, Stefan Stender, Frank J. Wolters, Albert Hofman & George Davey Smith. European Journal of Epidemiology. link.springer.com/article/10.1...

The rapid growth in Mendelian randomization studies - European Journal of Epidemiology
European Journal of Epidemiology -
link.springer.com
November 6, 2025 at 2:20 PM
The rapid growth in Mendelian randomization studies. Gibran Hemani, Stefan Stender, Frank J. Wolters, Albert Hofman & George Davey Smith. European Journal of Epidemiology. link.springer.com/article/10.1...
Reposted by Nik Tzoumas

Excited to share this preprint from first author Jon Rosen, a postdoctoral fellow in the @klmohlke.bsky.social lab and my lab. We examine eQTL study sample size and how this affects signal discovery and rates of colocalization with GWAS.
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...

Higher eQTL power reveals signals that boost GWAS colocalization
Expression quantitative trait locus (eQTL) studies in human cohorts typically detect at least one regulatory signal per gene, and have been proposed as a way to explain mechanisms of genetic liability...
www.biorxiv.org
August 18, 2025 at 12:18 PM
Excited to share this preprint from first author Jon Rosen, a postdoctoral fellow in the @klmohlke.bsky.social lab and my lab. We examine eQTL study sample size and how this affects signal discovery and rates of colocalization with GWAS.
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...
Reposted by Nik Tzoumas

I am genuinely impressed by large language models - they can absorb disparate components of text into some consolidated view, they can produce extremely good language and - with the right model - translate pretty well between languages and they are an excellent text based UI for humans to use. But..
October 26, 2025 at 7:48 AM
I am genuinely impressed by large language models - they can absorb disparate components of text into some consolidated view, they can produce extremely good language and - with the right model - translate pretty well between languages and they are an excellent text based UI for humans to use. But..
Reposted by Nik Tzoumas

For years I had trouble following some of the discussion about confidence bands, but at ACIC this year @noahgreifer.bsky.social pointed me to a helpful paper
So you don't have to be as perplexed as I once was, we have a new pre-print introducing the key ideas
arxiv.org/abs/2510.07076
So you don't have to be as perplexed as I once was, we have a new pre-print introducing the key ideas
arxiv.org/abs/2510.07076

Confidence Regions for Multiple Outcomes, Effect Modifiers, and Other Multiple Comparisons
In epidemiology, some have argued that multiple comparison corrections are not necessary as there is rarely interest in the universal null hypothesis. From a parameter estimation perspective, epidemio...
arxiv.org
October 9, 2025 at 3:34 PM
For years I had trouble following some of the discussion about confidence bands, but at ACIC this year @noahgreifer.bsky.social pointed me to a helpful paper
So you don't have to be as perplexed as I once was, we have a new pre-print introducing the key ideas
arxiv.org/abs/2510.07076
So you don't have to be as perplexed as I once was, we have a new pre-print introducing the key ideas
arxiv.org/abs/2510.07076
Reposted by Nik Tzoumas
Yongxi Long and colleagues have written an excellent post about when and when not to worry about the proportional odds assumption: discourse.datamethods.org/t/when-and-w... #StatsSky #EpiSky #Statistics #RStats
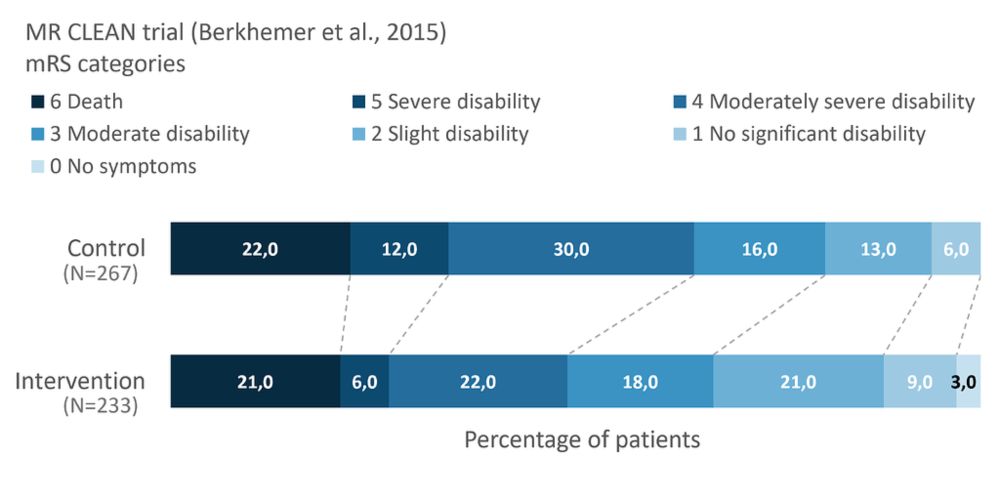
When and why (not) to worry about the PO assumption
Aim We wrote an article (Long, Wiegers, Jacobs, Steyerberg, & Van Zwet, 2025) about the proportional odds (PO) assumption in the analysis of ordinal outcomes. we use various examples from neurological...
discourse.datamethods.org
October 7, 2025 at 3:08 PM
Yongxi Long and colleagues have written an excellent post about when and when not to worry about the proportional odds assumption: discourse.datamethods.org/t/when-and-w... #StatsSky #EpiSky #Statistics #RStats
Reposted by Nik Tzoumas

Thank you for citing #tidyplots 🙏
Jakub Idkowiak et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nature Communications (2025).
doi.org/10.1038/s414...
#rstats #dataviz #phd
Jakub Idkowiak et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nature Communications (2025).
doi.org/10.1038/s414...
#rstats #dataviz #phd

Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data - Nature Communications
Mass spectrometry-based lipidomics and metabolomics generate large, complex datasets requiring effective analysis. Here, authors review key statistical and visualization methods alongside widely used R and Python tools, and provide a GitBook with step-by-step code for accessible, reproducible data analysis.
doi.org
October 1, 2025 at 3:05 PM
Thank you for citing #tidyplots 🙏
Jakub Idkowiak et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nature Communications (2025).
doi.org/10.1038/s414...
#rstats #dataviz #phd
Jakub Idkowiak et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nature Communications (2025).
doi.org/10.1038/s414...
#rstats #dataviz #phd