



Christian Laforte
@chrlaf.bsky.social
ML Engineer at NVIDIA. Previously: Stealth GPU startup; Stability AI; AMD; Autodesk; CEO of 2 startups (3D + AI). Toronto, Canada
Reposted by Christian Laforte

Z.AI's GLM-Image - open-weight
It uses a hybrid auto-regressive plus diffusion architecture, combining strong global semantic understanding with high fidelity visual detail. It matches mainstream diffusion models in overall quality while excelling at text rendering and knowledge intensive generati
It uses a hybrid auto-regressive plus diffusion architecture, combining strong global semantic understanding with high fidelity visual detail. It matches mainstream diffusion models in overall quality while excelling at text rendering and knowledge intensive generati

January 14, 2026 at 3:33 AM
Z.AI's GLM-Image - open-weight
It uses a hybrid auto-regressive plus diffusion architecture, combining strong global semantic understanding with high fidelity visual detail. It matches mainstream diffusion models in overall quality while excelling at text rendering and knowledge intensive generati
It uses a hybrid auto-regressive plus diffusion architecture, combining strong global semantic understanding with high fidelity visual detail. It matches mainstream diffusion models in overall quality while excelling at text rendering and knowledge intensive generati
I’d like access please! Simply having a separate app would help avoid overload of politics/general news. Thanks!

Something @eugenevinitsky.bsky.social and I are very curious about... how can we make our client (a version of Bluesky for researchers) more friendly to grad students? What would encourage you all to post more?
Things I miss from our custom client when I'm using Bluesky:
- avatar colors that show whether we're mutuals
- exportable bookmarks with custom folders
- feed of trending papers and articles
- safety alerts when a post goes viral
- researcher profiles with topics, affiliations, featured papers
- avatar colors that show whether we're mutuals
- exportable bookmarks with custom folders
- feed of trending papers and articles
- safety alerts when a post goes viral
- researcher profiles with topics, affiliations, featured papers
January 13, 2026 at 9:24 AM
I’d like access please! Simply having a separate app would help avoid overload of politics/general news. Thanks!
Reposted by Christian Laforte

Got our RL research codebase at @ai2.bsky.social running on my Nvidia DGX Spark. Fun times ahead and lots of learnings to share :)
January 13, 2026 at 1:47 AM
Got our RL research codebase at @ai2.bsky.social running on my Nvidia DGX Spark. Fun times ahead and lots of learnings to share :)
Reposted by Christian Laforte

Oh wow, deepseek is starting to make serious progress on LLMs that offload memory to external storage: github.com/deepseek-ai/...
github.com
January 12, 2026 at 6:44 PM
Oh wow, deepseek is starting to make serious progress on LLMs that offload memory to external storage: github.com/deepseek-ai/...
Reposted by Christian Laforte

One of my favorite findings: Positional embeddings are just training wheels. They help convergence but hurt long-context generalization.
We found that if you simply delete them after pretraining and recalibrate for <1% of the original budget, you unlock massive context windows. Smarter, not harder.
We found that if you simply delete them after pretraining and recalibrate for <1% of the original budget, you unlock massive context windows. Smarter, not harder.
Introducing DroPE: Extending Context by Dropping Positional Embeddings
We found embeddings like RoPE aid training but bottleneck long-sequence generalization. Our solution’s simple: treat them as a temporary training scaffold, not a permanent necessity.
arxiv.org/abs/2512.12167
pub.sakana.ai/DroPE
We found embeddings like RoPE aid training but bottleneck long-sequence generalization. Our solution’s simple: treat them as a temporary training scaffold, not a permanent necessity.
arxiv.org/abs/2512.12167
pub.sakana.ai/DroPE
January 12, 2026 at 4:12 AM
One of my favorite findings: Positional embeddings are just training wheels. They help convergence but hurt long-context generalization.
We found that if you simply delete them after pretraining and recalibrate for <1% of the original budget, you unlock massive context windows. Smarter, not harder.
We found that if you simply delete them after pretraining and recalibrate for <1% of the original budget, you unlock massive context windows. Smarter, not harder.
Reposted by Christian Laforte

Introducing DroPE: Extending Context by Dropping Positional Embeddings
We found embeddings like RoPE aid training but bottleneck long-sequence generalization. Our solution’s simple: treat them as a temporary training scaffold, not a permanent necessity.
arxiv.org/abs/2512.12167
pub.sakana.ai/DroPE
We found embeddings like RoPE aid training but bottleneck long-sequence generalization. Our solution’s simple: treat them as a temporary training scaffold, not a permanent necessity.
arxiv.org/abs/2512.12167
pub.sakana.ai/DroPE
January 12, 2026 at 4:07 AM
Introducing DroPE: Extending Context by Dropping Positional Embeddings
We found embeddings like RoPE aid training but bottleneck long-sequence generalization. Our solution’s simple: treat them as a temporary training scaffold, not a permanent necessity.
arxiv.org/abs/2512.12167
pub.sakana.ai/DroPE
We found embeddings like RoPE aid training but bottleneck long-sequence generalization. Our solution’s simple: treat them as a temporary training scaffold, not a permanent necessity.
arxiv.org/abs/2512.12167
pub.sakana.ai/DroPE
Reposted by Christian Laforte

When will we learn our lesson?? Our continued dependency on fossil fuel will not only kill people in the long term, it creates geopolitical instability and kills people in the short term. All to satisfy the greed of the broligarchy. We have the capability to move to carbon free sources.
January 6, 2026 at 12:31 PM
When will we learn our lesson?? Our continued dependency on fossil fuel will not only kill people in the long term, it creates geopolitical instability and kills people in the short term. All to satisfy the greed of the broligarchy. We have the capability to move to carbon free sources.
Reposted by Christian Laforte

“corrupt and kleptocratic government” fits Trump’s government eminently well, especially if you add “rogue aggressor with zero regard for international law”.
January 6, 2026 at 1:21 PM
“corrupt and kleptocratic government” fits Trump’s government eminently well, especially if you add “rogue aggressor with zero regard for international law”.
Reposted by Christian Laforte

We will either end fossil fuel dependency and the predatory extractivist basis of global production, or they will end us through wars and ecological collapse - all at the same time.
January 3, 2026 at 3:34 PM
We will either end fossil fuel dependency and the predatory extractivist basis of global production, or they will end us through wars and ecological collapse - all at the same time.
Reposted by Christian Laforte

If your president bombs Nigeria on Christmas just to distract from his crimes, you live in a shithole country.
December 26, 2025 at 3:56 AM
If your president bombs Nigeria on Christmas just to distract from his crimes, you live in a shithole country.
Reposted by Christian Laforte

This whale lives for centuries: its secret could help extend human lifespan www.nature.com/articles/d41...

This whale lives for centuries: its secret could help extend human lifespan
A cold-activated protein that mends damaged DNA could play a part in keeping the bowhead whale in tip-top shape.
www.nature.com
October 30, 2025 at 8:15 AM
This whale lives for centuries: its secret could help extend human lifespan www.nature.com/articles/d41...
Reposted by Christian Laforte

The world might be pulling back on climate truth: but I'm stepping it up.
How? I'm adding new videos, deep dives & behind-the-scenes stories to Talking Climate.
Why? Because climate honesty and hope matter more than ever right now.
Join me on Patreon: bit.ly/47pCLaf
Or Substack: bit.ly/4ntfvhJ
How? I'm adding new videos, deep dives & behind-the-scenes stories to Talking Climate.
Why? Because climate honesty and hope matter more than ever right now.
Join me on Patreon: bit.ly/47pCLaf
Or Substack: bit.ly/4ntfvhJ
October 28, 2025 at 3:41 PM
The world might be pulling back on climate truth: but I'm stepping it up.
How? I'm adding new videos, deep dives & behind-the-scenes stories to Talking Climate.
Why? Because climate honesty and hope matter more than ever right now.
Join me on Patreon: bit.ly/47pCLaf
Or Substack: bit.ly/4ntfvhJ
How? I'm adding new videos, deep dives & behind-the-scenes stories to Talking Climate.
Why? Because climate honesty and hope matter more than ever right now.
Join me on Patreon: bit.ly/47pCLaf
Or Substack: bit.ly/4ntfvhJ
Reposted by Christian Laforte

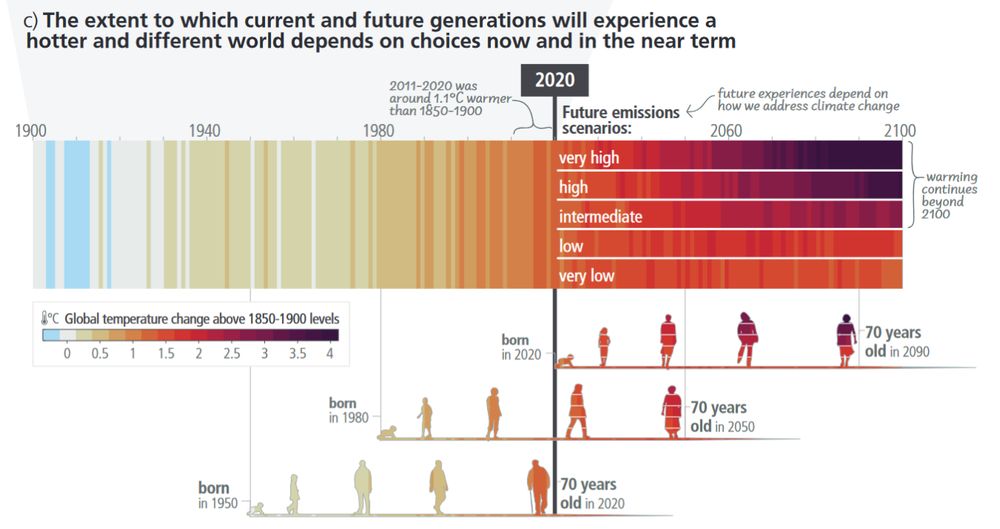
Climate action is not just about future generations. The choices we make today will help determine the climate impacts that people alive today, people in our lives, will experience over the rest of the century (and beyond).
June 25, 2025 at 4:24 PM
Climate action is not just about future generations. The choices we make today will help determine the climate impacts that people alive today, people in our lives, will experience over the rest of the century (and beyond).
Reposted by Christian Laforte

🎥 Real-time *infinite* video from just 1 frame?
Meet Seaweed-APT2: an 8B-param autoregressive GAN that streams 24fps video at 736×416—all in *1 network forward eval*. That’s 1440 frames/min, live, on a single H100 🚀
Project: seaweed-apt.com/2
Meet Seaweed-APT2: an 8B-param autoregressive GAN that streams 24fps video at 736×416—all in *1 network forward eval*. That’s 1440 frames/min, live, on a single H100 🚀
Project: seaweed-apt.com/2

Seaweed APT2
Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
seaweed-apt.com
June 23, 2025 at 3:46 PM
🎥 Real-time *infinite* video from just 1 frame?
Meet Seaweed-APT2: an 8B-param autoregressive GAN that streams 24fps video at 736×416—all in *1 network forward eval*. That’s 1440 frames/min, live, on a single H100 🚀
Project: seaweed-apt.com/2
Meet Seaweed-APT2: an 8B-param autoregressive GAN that streams 24fps video at 736×416—all in *1 network forward eval*. That’s 1440 frames/min, live, on a single H100 🚀
Project: seaweed-apt.com/2
Reposted by Christian Laforte

got scammed by this practice only by Adobe: no other SaaS did this with me before or after. I swear I signed up to a monthly plan: but in the fine print apparently it was “annual, paid monthly, cancel for a fee (that we won’t tell you how much it is).
Meanwhile the FTC: www.ftc.gov/news-events/...
Meanwhile the FTC: www.ftc.gov/news-events/...

FTC Takes Action Against Adobe and Executives for Hiding Fees, Preventing Consumers from Easily Cancelling Software Subscriptions
The Federal Trade Commission is taking action against software maker Adobe and two of its executives, Maninder Sawhney and David Wadhwani, for deceiving consumers by hiding the early terminati
www.ftc.gov
June 20, 2025 at 8:16 AM
got scammed by this practice only by Adobe: no other SaaS did this with me before or after. I swear I signed up to a monthly plan: but in the fine print apparently it was “annual, paid monthly, cancel for a fee (that we won’t tell you how much it is).
Meanwhile the FTC: www.ftc.gov/news-events/...
Meanwhile the FTC: www.ftc.gov/news-events/...
Reposted by Christian Laforte

...and if the ocean gets too acidic from CO2, the amount of oxygen in the air will decline and everyone will die!
People are always a bit surprised by that.
People are always a bit surprised by that.
June 17, 2025 at 4:08 AM
...and if the ocean gets too acidic from CO2, the amount of oxygen in the air will decline and everyone will die!
People are always a bit surprised by that.
People are always a bit surprised by that.
Reposted by Christian Laforte

My French side is always super proud when we are able to successfully export our national hobby to other countries! 🙃 Now let me introduce you to the concept of "unlimited general strike" 😝
June 15, 2025 at 7:03 AM
My French side is always super proud when we are able to successfully export our national hobby to other countries! 🙃 Now let me introduce you to the concept of "unlimited general strike" 😝
Reposted by Christian Laforte

Dear Americans, on behalf of all Canadians and citizens of the free world, thank you to everyone who turned out, for standing up against tyranny! 🙏

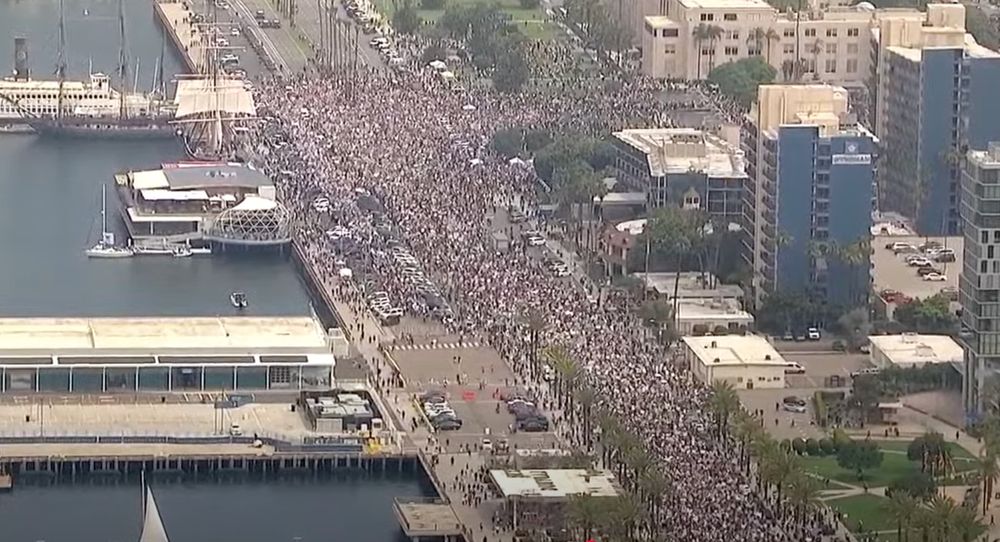

June 14, 2025 at 8:55 PM
Dear Americans, on behalf of all Canadians and citizens of the free world, thank you to everyone who turned out, for standing up against tyranny! 🙏
Reposted by Christian Laforte

I am heartbroken that I am not at the conference, but seeing what the government is doing to its people and the world, I simply couldn't go there.
June 14, 2025 at 9:51 AM
I am heartbroken that I am not at the conference, but seeing what the government is doing to its people and the world, I simply couldn't go there.
Reposted by Christian Laforte

This was me on the bus tonight. A @flomask.bsky.social respirator with a "Pro" filter equivalent to an N99 that is as easy to breathe through as most N95s.
I have equipped it with a @sipmask.bsky.social port so I can drink.
I have equipped it with a @sipmask.bsky.social port so I can drink.

June 13, 2025 at 4:15 AM
This was me on the bus tonight. A @flomask.bsky.social respirator with a "Pro" filter equivalent to an N99 that is as easy to breathe through as most N95s.
I have equipped it with a @sipmask.bsky.social port so I can drink.
I have equipped it with a @sipmask.bsky.social port so I can drink.
Reposted by Christian Laforte

Editing appearance, geometry, lighting with precision is easy with a 3D scene representation. But it's so much more difficult with just an image or photograph.
Enter IntrinsicEdit: Precise generative image manipulation in intrinsic space (SIGGRAPH 2025)!
intrinsic-edit.github.io
Enter IntrinsicEdit: Precise generative image manipulation in intrinsic space (SIGGRAPH 2025)!
intrinsic-edit.github.io

IntrinsicEdit: Precise generative image manipulation in intrinsic space
We present a powerful generative editing workflow built on the RGB-X diffusion framework, enabling pixel-precise, semantic image manipulation across tasks like relighting, color adjustment, and object...
intrinsic-edit.github.io
June 12, 2025 at 9:10 PM
Editing appearance, geometry, lighting with precision is easy with a 3D scene representation. But it's so much more difficult with just an image or photograph.
Enter IntrinsicEdit: Precise generative image manipulation in intrinsic space (SIGGRAPH 2025)!
intrinsic-edit.github.io
Enter IntrinsicEdit: Precise generative image manipulation in intrinsic space (SIGGRAPH 2025)!
intrinsic-edit.github.io
Reposted by Christian Laforte

A teaser of the latest 3D DUSt3R based models we’re presenting at @cvprconference.bsky.social
Discover MUSt3R & Pow3R, universal encoder DUNE + research in navigation, vizloc, segmentation & human motion understanding!
All our #CVPR2025 papers are here
➡️ tinyurl.com/4z79ujce
Discover MUSt3R & Pow3R, universal encoder DUNE + research in navigation, vizloc, segmentation & human motion understanding!
All our #CVPR2025 papers are here
➡️ tinyurl.com/4z79ujce
June 11, 2025 at 4:11 PM
A teaser of the latest 3D DUSt3R based models we’re presenting at @cvprconference.bsky.social
Discover MUSt3R & Pow3R, universal encoder DUNE + research in navigation, vizloc, segmentation & human motion understanding!
All our #CVPR2025 papers are here
➡️ tinyurl.com/4z79ujce
Discover MUSt3R & Pow3R, universal encoder DUNE + research in navigation, vizloc, segmentation & human motion understanding!
All our #CVPR2025 papers are here
➡️ tinyurl.com/4z79ujce
Reposted by Christian Laforte
New study investigates the prevalence of misinformation about EVs in four countries – Australia, the United States, Germany and Austria. They found substantial levels of misinformed beliefs across all countries. Here are the 9 top EV myths:


June 10, 2025 at 8:14 PM
New study investigates the prevalence of misinformation about EVs in four countries – Australia, the United States, Germany and Austria. They found substantial levels of misinformed beliefs across all countries. Here are the 9 top EV myths:
Reposted by Christian Laforte

Here are all the CVPR projects that I’m part of in one thread.
Conference papers:
PromptHMR: Promptable Human Mesh Recovery
yufu-wang.github.io/phmr-page/
DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
radualexandru.github.io/difflocks/
Conference papers:
PromptHMR: Promptable Human Mesh Recovery
yufu-wang.github.io/phmr-page/
DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
radualexandru.github.io/difflocks/

June 9, 2025 at 8:05 AM
Here are all the CVPR projects that I’m part of in one thread.
Conference papers:
PromptHMR: Promptable Human Mesh Recovery
yufu-wang.github.io/phmr-page/
DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
radualexandru.github.io/difflocks/
Conference papers:
PromptHMR: Promptable Human Mesh Recovery
yufu-wang.github.io/phmr-page/
DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
radualexandru.github.io/difflocks/
Reposted by Christian Laforte

I'm late to review the "Illusion of Thinking" paper, so let me collect some of the best threads by and critical takes by @scaling01 in one place and sprinkle some of my own thoughts in as well.
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar...
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar...
June 9, 2025 at 9:49 PM
I'm late to review the "Illusion of Thinking" paper, so let me collect some of the best threads by and critical takes by @scaling01 in one place and sprinkle some of my own thoughts in as well.
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar...
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar...