



Manya Wadhwa
@manyawadhwa.bsky.social
Pinned
Manya Wadhwa
@manyawadhwa.bsky.social
· Apr 22

Evaluating language model responses on open-ended tasks is hard! 🤔
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
Reposted by Manya Wadhwa

N-gram novelty is widely used as a measure of creativity and generalization. But if LLMs produce highly n-gram novel expressions that don’t make sense or sound awkward, should they still be called creative? In a new paper, we investigate how n-gram novelty relates to creativity.

November 4, 2025 at 3:08 PM
N-gram novelty is widely used as a measure of creativity and generalization. But if LLMs produce highly n-gram novel expressions that don’t make sense or sound awkward, should they still be called creative? In a new paper, we investigate how n-gram novelty relates to creativity.
Reposted by Manya Wadhwa

AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:

October 22, 2025 at 3:24 PM
AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
Reposted by Manya Wadhwa

🚨New paper on AI & copyright
Authors have sued LLM companies for using books w/o permission for model training.
Courts however need empirical evidence of market harm. Our preregistered study exactly addresses this gap.
Joint work w Jane Ginsburg from Columbia Law and @dhillonp.bsky.social 1/n🧵
Authors have sued LLM companies for using books w/o permission for model training.
Courts however need empirical evidence of market harm. Our preregistered study exactly addresses this gap.
Joint work w Jane Ginsburg from Columbia Law and @dhillonp.bsky.social 1/n🧵

October 22, 2025 at 4:54 PM
🚨New paper on AI & copyright
Authors have sued LLM companies for using books w/o permission for model training.
Courts however need empirical evidence of market harm. Our preregistered study exactly addresses this gap.
Joint work w Jane Ginsburg from Columbia Law and @dhillonp.bsky.social 1/n🧵
Authors have sued LLM companies for using books w/o permission for model training.
Courts however need empirical evidence of market harm. Our preregistered study exactly addresses this gap.
Joint work w Jane Ginsburg from Columbia Law and @dhillonp.bsky.social 1/n🧵
Reposted by Manya Wadhwa

UT Austin Linguistics is hiring in computational linguistics!
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
UT Austin Computational Linguistics Research Group – Humans processing computers processing humans processing language
sites.utexas.edu
October 7, 2025 at 8:53 PM
UT Austin Linguistics is hiring in computational linguistics!
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
Reposted by Manya Wadhwa

Find my students and collaborators at COLM this week!
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster

October 7, 2025 at 6:03 PM
Find my students and collaborators at COLM this week!
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
Unfortunately I won't be at #COLM2025 this week, but please check out our work being presented by my collaborators/advisors!
If you are interested in evals of open-ended tasks/creativity please reach out and we can schedule a chat! :)
If you are interested in evals of open-ended tasks/creativity please reach out and we can schedule a chat! :)
Find my students and collaborators at COLM this week!
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
October 8, 2025 at 12:19 AM
Unfortunately I won't be at #COLM2025 this week, but please check out our work being presented by my collaborators/advisors!
If you are interested in evals of open-ended tasks/creativity please reach out and we can schedule a chat! :)
If you are interested in evals of open-ended tasks/creativity please reach out and we can schedule a chat! :)
Reposted by Manya Wadhwa

Excited to present this at #COLM2025 tomorrow! (Tuesday, 11:00 AM poster session)
One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇


October 6, 2025 at 8:40 PM
Excited to present this at #COLM2025 tomorrow! (Tuesday, 11:00 AM poster session)
Reposted by Manya Wadhwa

Come to talk with us today about the evaluation of long form multilingual generation at the second poster session #COLM2025
📍4:30–6:30 PM / Room 710 – Poster #8
📍4:30–6:30 PM / Room 710 – Poster #8

October 7, 2025 at 5:54 PM
Come to talk with us today about the evaluation of long form multilingual generation at the second poster session #COLM2025
📍4:30–6:30 PM / Room 710 – Poster #8
📍4:30–6:30 PM / Room 710 – Poster #8
Reposted by Manya Wadhwa

Ever wondered what makes language models generate overly verbose, vague, or sycophantic responses?
Our new paper investigates these and other idiosyncratic biases in preference models, and presents a simple post-training recipe to mitigate them! Thread below 🧵↓
Our new paper investigates these and other idiosyncratic biases in preference models, and presents a simple post-training recipe to mitigate them! Thread below 🧵↓

June 6, 2025 at 4:32 PM
Ever wondered what makes language models generate overly verbose, vague, or sycophantic responses?
Our new paper investigates these and other idiosyncratic biases in preference models, and presents a simple post-training recipe to mitigate them! Thread below 🧵↓
Our new paper investigates these and other idiosyncratic biases in preference models, and presents a simple post-training recipe to mitigate them! Thread below 🧵↓
Reposted by Manya Wadhwa

Extremely excited to announce that I will be joining
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉

May 5, 2025 at 8:28 PM
Extremely excited to announce that I will be joining
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉
Reposted by Manya Wadhwa

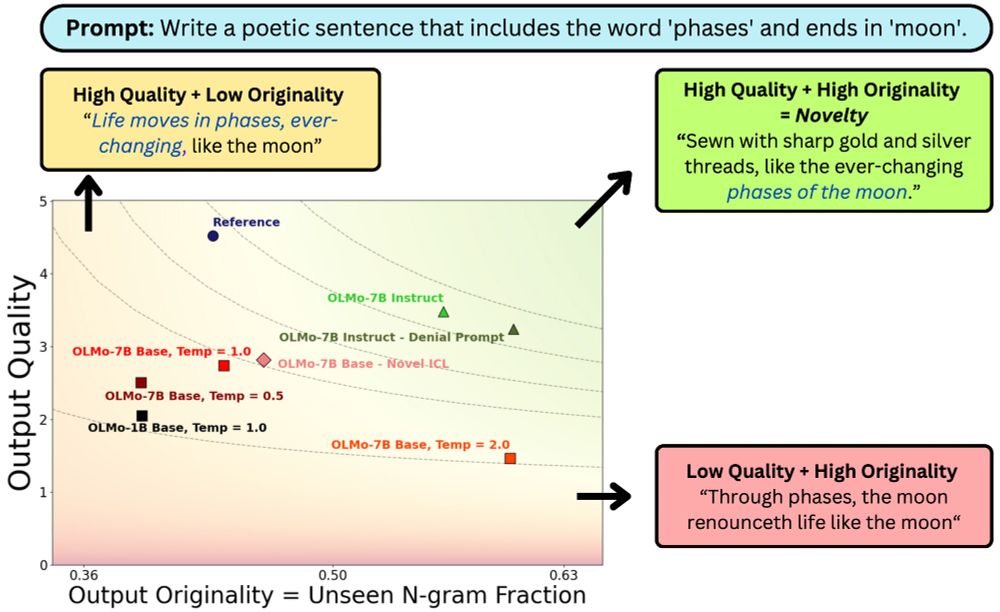
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
April 29, 2025 at 4:35 PM
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
Reposted by Manya Wadhwa
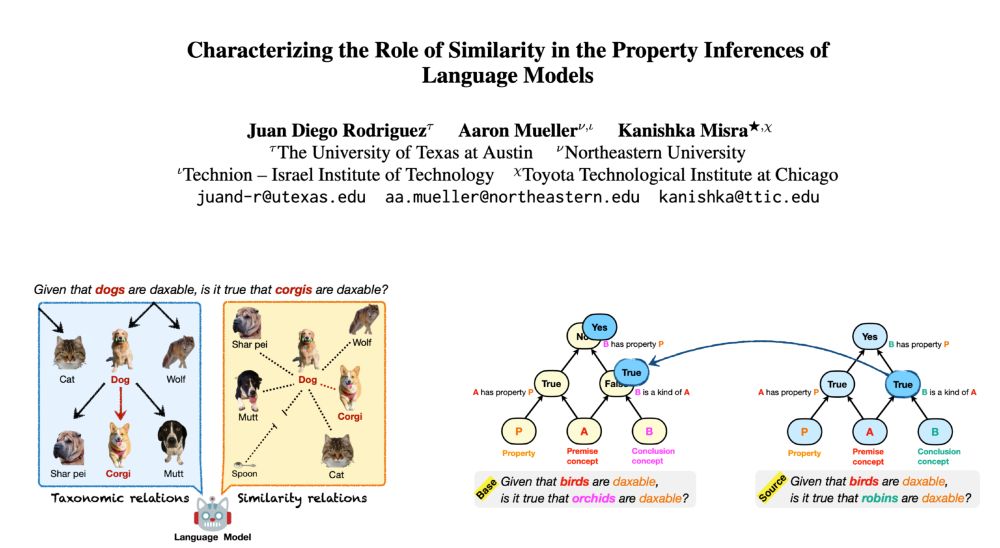
How do language models organize concepts and their properties? Do they use taxonomies to infer new properties, or infer based on concept similarities? Apparently, both!
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
November 8, 2024 at 9:40 PM
How do language models organize concepts and their properties? Do they use taxonomies to infer new properties, or infer based on concept similarities? Apparently, both!
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
Reposted by Manya Wadhwa

If you are at #NAACL2025 @naaclmeeting.bsky.social catch @juand-r.bsky.social presenting our poster on the interplay between similarity and category membership in the property inferences of LMs @ Poster Session 1 on Wednesday!
Or if you're at home like me, read our paper: arxiv.org/abs/2410.22590
Or if you're at home like me, read our paper: arxiv.org/abs/2410.22590
How do language models organize concepts and their properties? Do they use taxonomies to infer new properties, or infer based on concept similarities? Apparently, both!
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
April 28, 2025 at 1:40 AM
If you are at #NAACL2025 @naaclmeeting.bsky.social catch @juand-r.bsky.social presenting our poster on the interplay between similarity and category membership in the property inferences of LMs @ Poster Session 1 on Wednesday!
Or if you're at home like me, read our paper: arxiv.org/abs/2410.22590
Or if you're at home like me, read our paper: arxiv.org/abs/2410.22590
Reposted by Manya Wadhwa

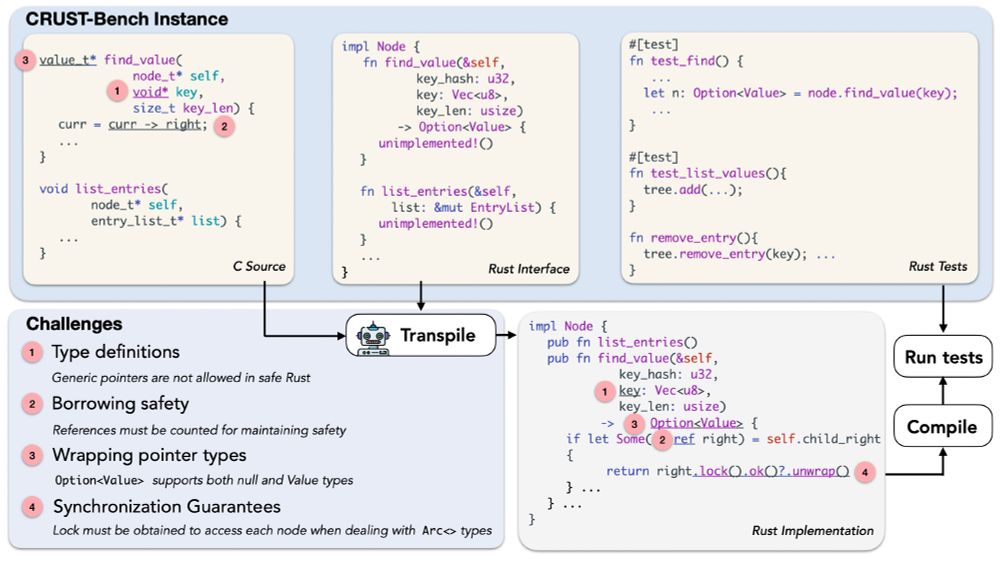
🚀Meet CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]

April 23, 2025 at 5:00 PM
🚀Meet CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
Evaluating language model responses on open-ended tasks is hard! 🤔
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
April 22, 2025 at 3:04 PM
Evaluating language model responses on open-ended tasks is hard! 🤔
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
Reposted by Manya Wadhwa
One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
April 16, 2025 at 6:03 PM
One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
Reposted by Manya Wadhwa
1.) [NAACL 25] @kanishka.bsky.social, @amuuueller.bsky.social and I delve into how language models do property inheritance using behavioral and mechanistic analyses.
Thank you, Kanishka and Aaron. I could not have hoped for better collaborators! arxiv.org/abs/2410.22590
[👇 bsky.app/profile/juan...
Thank you, Kanishka and Aaron. I could not have hoped for better collaborators! arxiv.org/abs/2410.22590
[👇 bsky.app/profile/juan...
March 11, 2025 at 10:03 PM
1.) [NAACL 25] @kanishka.bsky.social, @amuuueller.bsky.social and I delve into how language models do property inheritance using behavioral and mechanistic analyses.
Thank you, Kanishka and Aaron. I could not have hoped for better collaborators! arxiv.org/abs/2410.22590
[👇 bsky.app/profile/juan...
Thank you, Kanishka and Aaron. I could not have hoped for better collaborators! arxiv.org/abs/2410.22590
[👇 bsky.app/profile/juan...
Reposted by Manya Wadhwa

LLM judges have become ubiquitous, but valuable signal is often ignored at inference.
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)

March 6, 2025 at 2:32 PM
LLM judges have become ubiquitous, but valuable signal is often ignored at inference.
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
Reposted by Manya Wadhwa

Do you want to know what information LLMs prioritize in text synthesis tasks? Here's a short 🧵 about our new paper, led by Jan Trienes: an interpretable framework for salience analysis in LLMs.
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)

February 21, 2025 at 6:15 PM
Do you want to know what information LLMs prioritize in text synthesis tasks? Here's a short 🧵 about our new paper, led by Jan Trienes: an interpretable framework for salience analysis in LLMs.
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
Reposted by Manya Wadhwa

⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
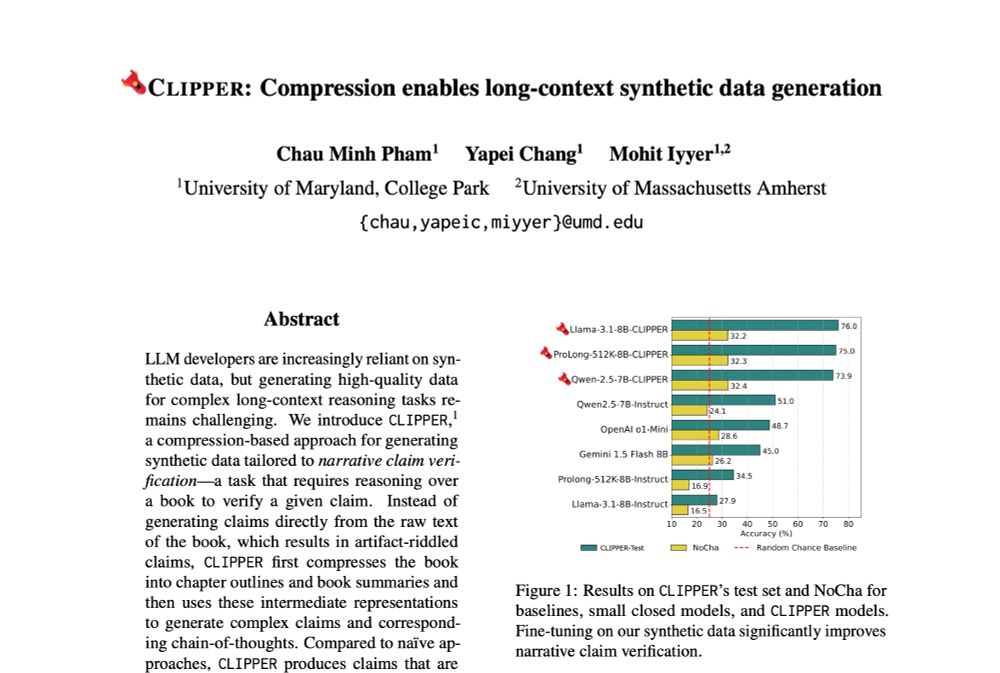
February 21, 2025 at 4:25 PM
⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
Reposted by Manya Wadhwa
Excited that this got accepted at naacl/@naaclmeeting.bsky.social 2025! Massive kudos to Juan Diego and Aaron for being the best co-authors and colleagues one could ask for! 🙏
How do language models organize concepts and their properties? Do they use taxonomies to infer new properties, or infer based on concept similarities? Apparently, both!
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
January 23, 2025 at 12:02 AM
Excited that this got accepted at naacl/@naaclmeeting.bsky.social 2025! Massive kudos to Juan Diego and Aaron for being the best co-authors and colleagues one could ask for! 🙏
Reposted by Manya Wadhwa

I'm at #Neurips2024 this week!
My work (arxiv.org/abs/2406.17692) w/ @gregdnlp.bsky.social & @eunsol.bsky.social exploring the connection between LLM alignment and response pluralism will be at pluralistic-alignment.github.io Saturday. Drop by to learn more!
My work (arxiv.org/abs/2406.17692) w/ @gregdnlp.bsky.social & @eunsol.bsky.social exploring the connection between LLM alignment and response pluralism will be at pluralistic-alignment.github.io Saturday. Drop by to learn more!

December 11, 2024 at 5:39 PM
I'm at #Neurips2024 this week!
My work (arxiv.org/abs/2406.17692) w/ @gregdnlp.bsky.social & @eunsol.bsky.social exploring the connection between LLM alignment and response pluralism will be at pluralistic-alignment.github.io Saturday. Drop by to learn more!
My work (arxiv.org/abs/2406.17692) w/ @gregdnlp.bsky.social & @eunsol.bsky.social exploring the connection between LLM alignment and response pluralism will be at pluralistic-alignment.github.io Saturday. Drop by to learn more!
Reposted by Manya Wadhwa

I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.
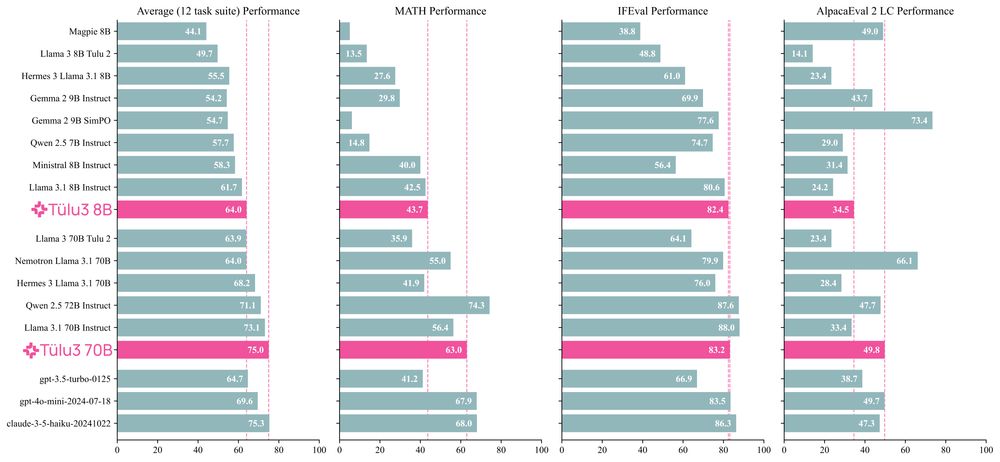
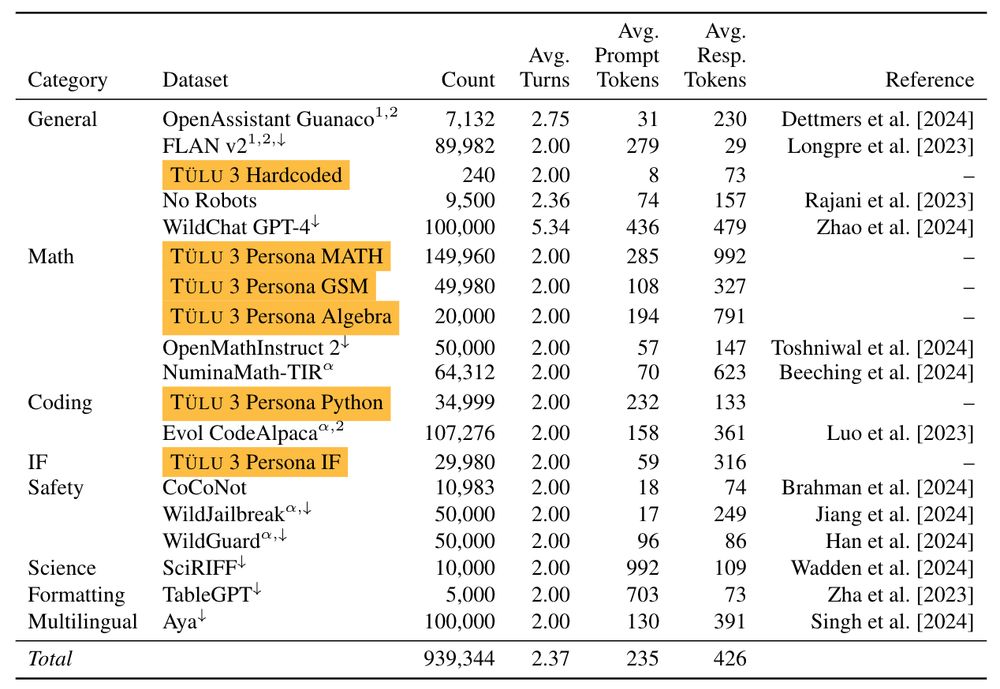
November 21, 2024 at 5:01 PM
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.
Reposted by Manya Wadhwa
We at UT Linguistics are hiring for 🔥 2 faculty positions in Computational Linguistics! Assistant or Associate professors, deadline Dec 1.
UT has a super vibrant comp ling & #nlp community!!
Apply here 👉 apply.interfolio.com/158280
UT has a super vibrant comp ling & #nlp community!!
Apply here 👉 apply.interfolio.com/158280
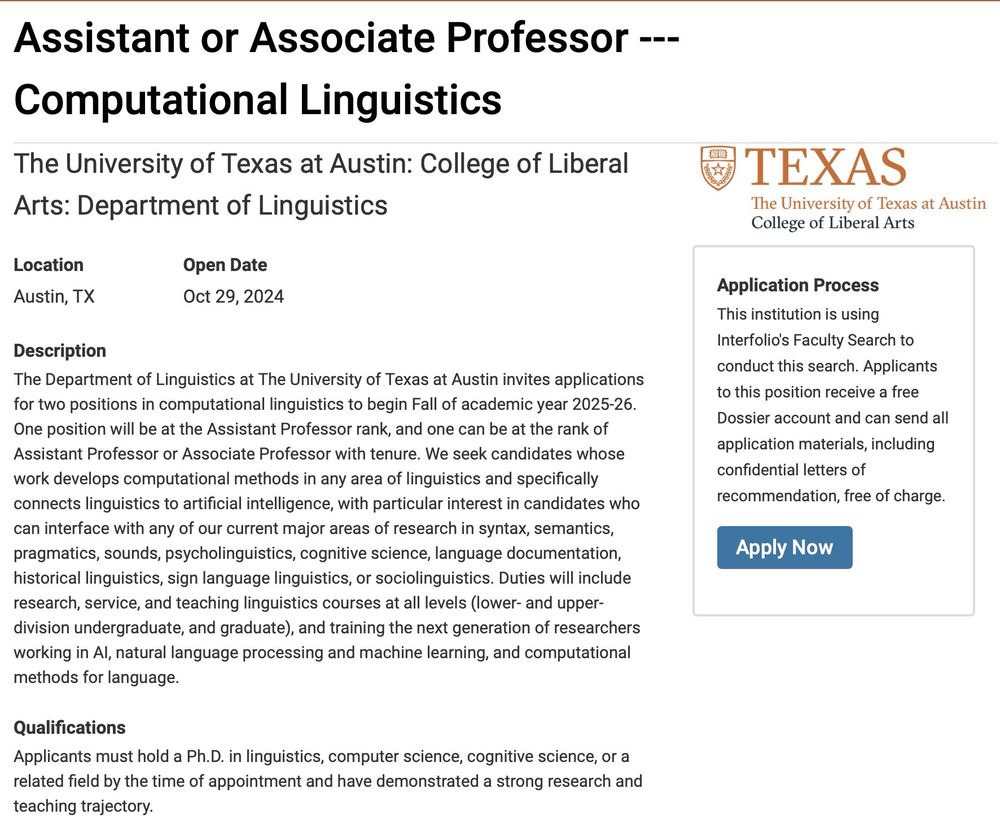
November 19, 2024 at 10:45 PM
We at UT Linguistics are hiring for 🔥 2 faculty positions in Computational Linguistics! Assistant or Associate professors, deadline Dec 1.
UT has a super vibrant comp ling & #nlp community!!
Apply here 👉 apply.interfolio.com/158280
UT has a super vibrant comp ling & #nlp community!!
Apply here 👉 apply.interfolio.com/158280
Reposted by Manya Wadhwa

1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
November 19, 2024 at 4:30 PM
1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai