Adhiraj Ghosh@ACL2025
@adhirajghosh.bsky.social
1.5K followers
420 following
78 posts
ELLIS PhD, University of Tübingen | Data-centric Vision and Language @bethgelab.bsky.social
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
Posts
Media
Videos
Starter Packs
Pinned




Reposted by Adhiraj Ghosh@ACL2025


Reposted by Adhiraj Ghosh@ACL2025

Reposted by Adhiraj Ghosh@ACL2025



Reposted by Adhiraj Ghosh@ACL2025


Reposted by Adhiraj Ghosh@ACL2025

Thaddäus Wiedemer
@thwiedemer.bsky.social
· Feb 18

Reposted by Adhiraj Ghosh@ACL2025


Reposted by Adhiraj Ghosh@ACL2025

Reposted by Adhiraj Ghosh@ACL2025

Reposted by Adhiraj Ghosh@ACL2025

Sebastian Dziadzio
@dziadzio.bsky.social
· Dec 11

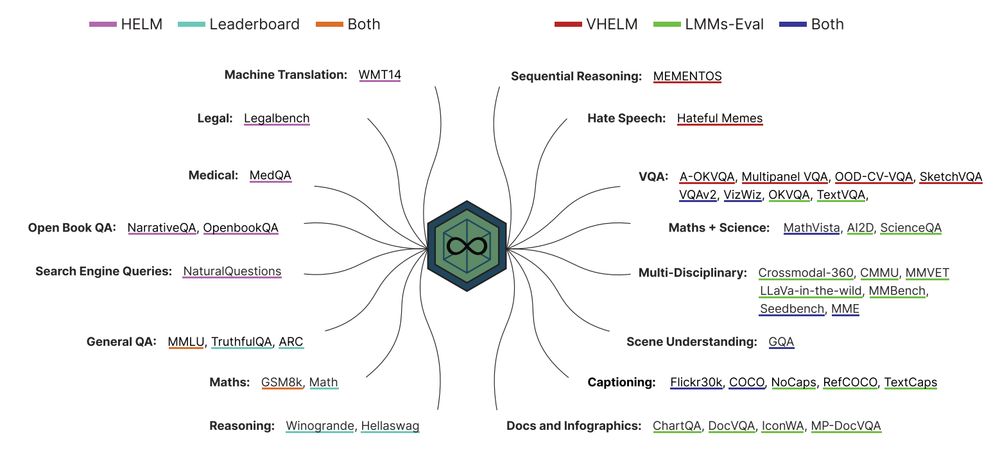
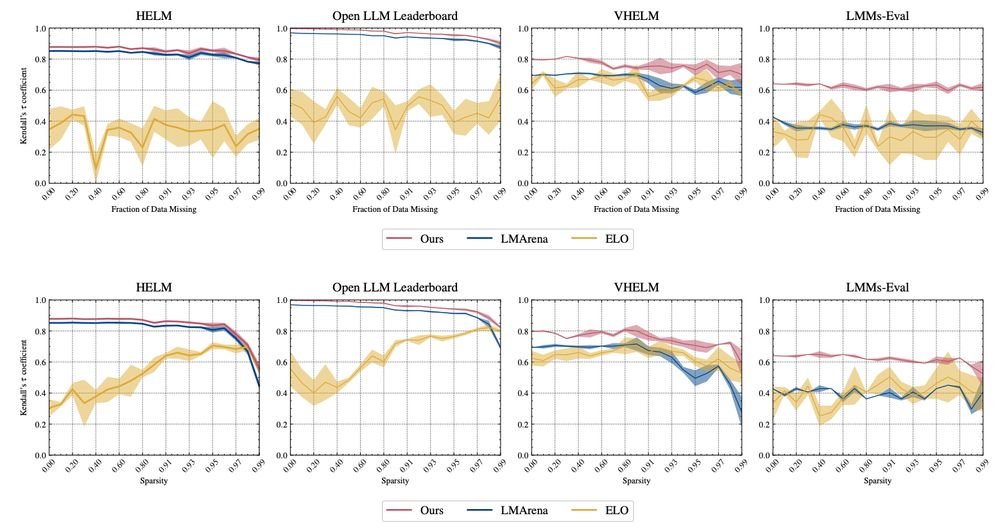
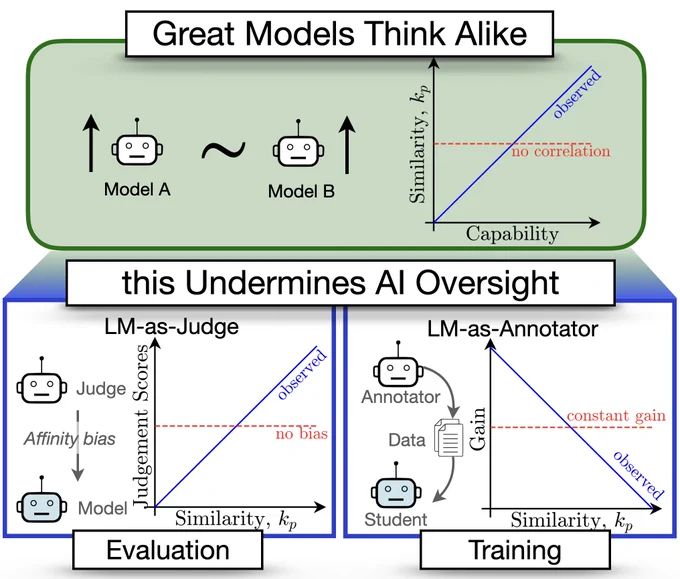
How to Merge Your Multimodal Models Over Time?
Model merging combines multiple expert models - finetuned from a base foundation model on diverse tasks and domains - into a single, more capable model. However, most existing model merging approaches...
arxiv.org
Reposted by Adhiraj Ghosh@ACL2025
Ameya P.
@bayesiankitten.bsky.social
· Dec 10