



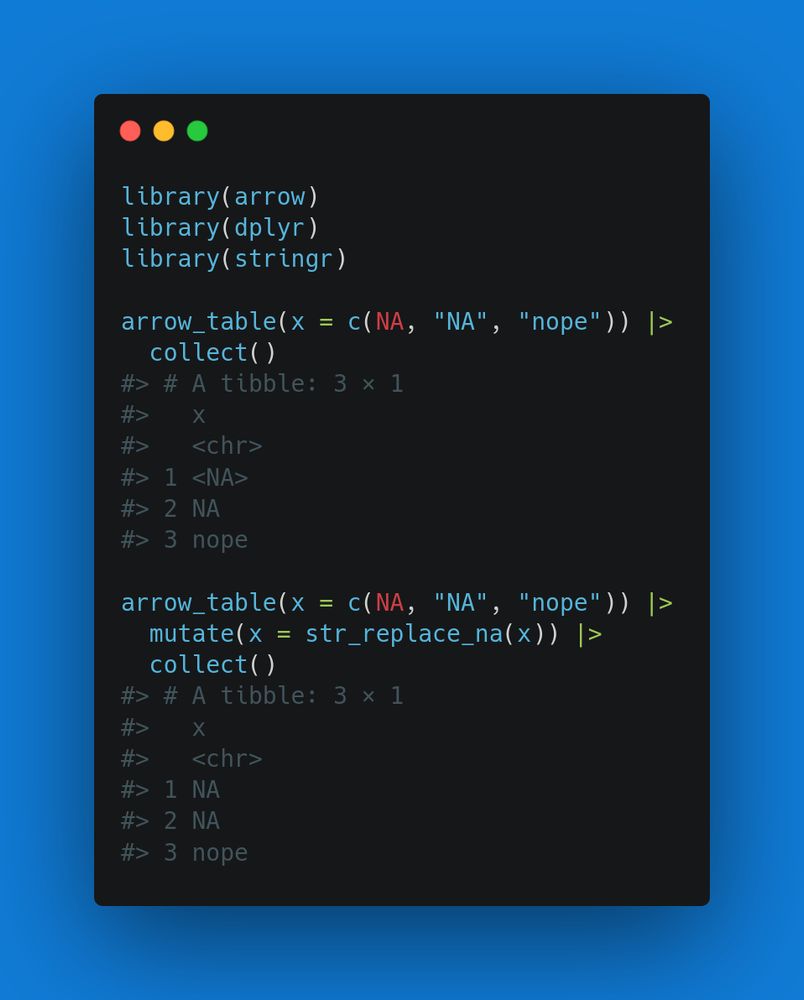
Most updates were to docs and internals, but one feature to note is that we’ve added support for stringr::str_replace_na()
November 6, 2025 at 10:02 AM
Most updates were to docs and internals, but one feature to note is that we’ve added support for stringr::str_replace_na()



And stringr 1.6.0 is out too: tidyverse.org/blog/2025/11.... A fairly small release but some handy improvements thanks to tidyverse dev day contributors! #rstats

stringr 1.6.0
This release deprecates `str_like(ignore_case)` and changes the behaviour of `str_replace_all()` for function replacements. It also introduces `str_ilike()` for case-insensitive SQL-like pattern matc...
tidyverse.org
November 4, 2025 at 10:45 PM
And stringr 1.6.0 is out too: tidyverse.org/blog/2025/11.... A fairly small release but some handy improvements thanks to tidyverse dev day contributors! #rstats

Updates on CRAN: NMdata (0.2.2), purrr (1.2.0), sspse (1.1.0-3), stringr (1.6.0), tepr (1.1.12)
November 4, 2025 at 5:19 PM
Updates on CRAN: NMdata (0.2.2), purrr (1.2.0), sspse (1.1.0-3), stringr (1.6.0), tepr (1.1.12)


STRiNGRファンにとって至高の経験すぎるし行かない選択肢ないねこれは
October 23, 2025 at 12:10 PM
STRiNGRファンにとって至高の経験すぎるし行かない選択肢ないねこれは

@statsepi.bsky.social
stringr::str_split(string, ",(?! )", simplify = TRUE)
stringr::str_split(string, ",(?! )", simplify = TRUE)
October 9, 2025 at 3:57 PM
@statsepi.bsky.social
stringr::str_split(string, ",(?! )", simplify = TRUE)
stringr::str_split(string, ",(?! )", simplify = TRUE)

Seems like this works?

October 9, 2025 at 3:05 PM
Seems like this works?

stringr::str_detect is all you need
October 9, 2025 at 2:55 PM
stringr::str_detect is all you need

Text Analytics in R with quanteda (Part 1)
"Required Packages
library(quanteda)
library(quanteda.textstats)
library(quanteda.textplots)
library(readr)
library(dplyr)
library(ggplot2)
library(stringr)
library(DT)
library(tidytext)
Understanding Text Analytics Fundamentals
Text analytic...
Co..."
"Required Packages
library(quanteda)
library(quanteda.textstats)
library(quanteda.textplots)
library(readr)
library(dplyr)
library(ggplot2)
library(stringr)
library(DT)
library(tidytext)
Understanding Text Analytics Fundamentals
Text analytic...
Co..."
October 14, 2025 at 4:37 PM
Text Analytics in R with quanteda (Part 1)
"Required Packages
library(quanteda)
library(quanteda.textstats)
library(quanteda.textplots)
library(readr)
library(dplyr)
library(ggplot2)
library(stringr)
library(DT)
library(tidytext)
Understanding Text Analytics Fundamentals
Text analytic...
Co..."
"Required Packages
library(quanteda)
library(quanteda.textstats)
library(quanteda.textplots)
library(readr)
library(dplyr)
library(ggplot2)
library(stringr)
library(DT)
library(tidytext)
Understanding Text Analytics Fundamentals
Text analytic...
Co..."

If you ever find yourself needing to write something dependency free, but you usually use `stringr`, bookmark this bad boy
stringr.tidyverse.org/articles/fro...
stringr.tidyverse.org/articles/fro...

From base R
stringr
stringr.tidyverse.org
October 2, 2025 at 6:08 PM
If you ever find yourself needing to write something dependency free, but you usually use `stringr`, bookmark this bad boy
stringr.tidyverse.org/articles/fro...
stringr.tidyverse.org/articles/fro...

x <- c("8", "10", "1", "40", "9A", "21A", "21B")
stringr::str_sort(x, numeric = TRUE)
[1] "1" "8" "9A" "10" "21A" "21B" "40"
stringr::str_sort(x, numeric = TRUE)
[1] "1" "8" "9A" "10" "21A" "21B" "40"
October 1, 2025 at 7:53 PM
x <- c("8", "10", "1", "40", "9A", "21A", "21B")
stringr::str_sort(x, numeric = TRUE)
[1] "1" "8" "9A" "10" "21A" "21B" "40"
stringr::str_sort(x, numeric = TRUE)
[1] "1" "8" "9A" "10" "21A" "21B" "40"

I like str_wrap() too from {stringr}.
October 1, 2025 at 5:14 PM
I like str_wrap() too from {stringr}.
Just learned: It's so easy to sort strings that are numbers in proper numerical order with the {stringr} #Rstats 📦's `str_sort()` function and numeric = TRUE!!
x <- c("8", "10", "1", "40")
str_sort(x, numeric = TRUE)
[1] "1" "8" "10" "40"
x <- c("8", "10", "1", "40")
str_sort(x, numeric = TRUE)
[1] "1" "8" "10" "40"
October 1, 2025 at 4:53 PM
Just learned: It's so easy to sort strings that are numbers in proper numerical order with the {stringr} #Rstats 📦's `str_sort()` function and numeric = TRUE!!
x <- c("8", "10", "1", "40")
str_sort(x, numeric = TRUE)
[1] "1" "8" "10" "40"
x <- c("8", "10", "1", "40")
str_sort(x, numeric = TRUE)
[1] "1" "8" "10" "40"

10/
Key takeaways:
awk = lightweight, precise
csvtk = robust, CSV-aware
stringr = complex logic in R
Always validate after replacing. Mistakes here can cost you a week.
Key takeaways:
awk = lightweight, precise
csvtk = robust, CSV-aware
stringr = complex logic in R
Always validate after replacing. Mistakes here can cost you a week.
September 27, 2025 at 1:45 PM
10/
Key takeaways:
awk = lightweight, precise
csvtk = robust, CSV-aware
stringr = complex logic in R
Always validate after replacing. Mistakes here can cost you a week.
Key takeaways:
awk = lightweight, precise
csvtk = robust, CSV-aware
stringr = complex logic in R
Always validate after replacing. Mistakes here can cost you a week.
6/
Prefer R?
For more complex regex:
library(stringr)
df$V5 <- str_replace(df$V5, "pattern", "replacement")
Want to go further? Use str_replace_all() or mutate() from dplyr.
Prefer R?
For more complex regex:
library(stringr)
df$V5 <- str_replace(df$V5, "pattern", "replacement")
Want to go further? Use str_replace_all() or mutate() from dplyr.
September 27, 2025 at 1:45 PM
6/
Prefer R?
For more complex regex:
library(stringr)
df$V5 <- str_replace(df$V5, "pattern", "replacement")
Want to go further? Use str_replace_all() or mutate() from dplyr.
Prefer R?
For more complex regex:
library(stringr)
df$V5 <- str_replace(df$V5, "pattern", "replacement")
Want to go further? Use str_replace_all() or mutate() from dplyr.

the way that namespaced functions get automatically translated to SQL if the package author's support that function translation... is weird magic
con <- DBI::dbConnect(duckdb::duckdb())
dbplyr::translate_sql(stringr::str_trim(x), con = con)
#> LTRIM(RTRIM(x))
con <- DBI::dbConnect(duckdb::duckdb())
dbplyr::translate_sql(stringr::str_trim(x), con = con)
#>
September 16, 2025 at 8:08 PM
the way that namespaced functions get automatically translated to SQL if the package author's support that function translation... is weird magic
con <- DBI::dbConnect(duckdb::duckdb())
dbplyr::translate_sql(stringr::str_trim(x), con = con)
#> LTRIM(RTRIM(x))
con <- DBI::dbConnect(duckdb::duckdb())
dbplyr::translate_sql(stringr::str_trim(x), con = con)
#>

Wtf why is the remove NA functionality not default behaviour in stringr::str_c
Also thank you, I did not know about this function
Also thank you, I did not know about this function
September 13, 2025 at 2:01 AM
Wtf why is the remove NA functionality not default behaviour in stringr::str_c
Also thank you, I did not know about this function
Also thank you, I did not know about this function
I don't know how messy your school names are and you may already have this data taken care of! But the {stringr} functions in #rstats are really handy! They won't take care of misspellings though. :(

September 9, 2025 at 7:30 PM
I don't know how messy your school names are and you may already have this data taken care of! But the {stringr} functions in #rstats are really handy! They won't take care of misspellings though. :(
Updates on CRAN: bigalgebra (2.0.2), MKMeans (3.4.4), shortIRT (0.1.4), stringr (1.5.2)
September 8, 2025 at 1:26 PM
Updates on CRAN: bigalgebra (2.0.2), MKMeans (3.4.4), shortIRT (0.1.4), stringr (1.5.2)
14/
Key takeaways:
• Regex cleans messy data fast
• Works on gene IDs, labels, metadata
• Combine with stringr for clarity
Key takeaways:
• Regex cleans messy data fast
• Works on gene IDs, labels, metadata
• Combine with stringr for clarity
September 3, 2025 at 1:45 PM
14/
Key takeaways:
• Regex cleans messy data fast
• Works on gene IDs, labels, metadata
• Combine with stringr for clarity
Key takeaways:
• Regex cleans messy data fast
• Works on gene IDs, labels, metadata
• Combine with stringr for clarity
Ever need to count the number of characters in a variable (sometimes based on a pattern)? The #rstats {stringr} package is great for that. ✨
cghlewis.github.io/data-wrangli...
cghlewis.github.io/data-wrangli...

![d12
# A tibble: 4 x 2
id item1
<dbl> <chr>
1 1 "c,a,p"
2 2 "a,p"
3 3 ""
4 4 "p"
Same as above, item1 represents student responses of a word. Each letter represents a correct phonetic sound. We want to count the number of correct sounds for each student. However, this time, our data has commas between letters so we cannot use stringr::str_length() because it will count the commas, giving us incorrect scores.
Instead we use stringr::str_count() and add the argument pattern = and we add the regex pattern “[a-z]” which says to count any lowercase letter a to z.
d12 %>%
dplyr::mutate(item1_score = stringr::str_count(item1, pattern = "[a-z]"))
# A tibble: 4 x 3
id item1 item1_score
<dbl> <chr> <int>
1 1 "c,a,p" 3
2 2 "a,p" 2
3 3 "" 0
4 4 "p" 1](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:zxaobre6qygeskx6nr2ew6lu/bafkreihh7fq44agdetkgp4gqdmlrrtaeooxibijl6wwcvxhxb7rrvyxyvi@jpeg)
August 29, 2025 at 11:09 AM
Ever need to count the number of characters in a variable (sometimes based on a pattern)? The #rstats {stringr} package is great for that. ✨
cghlewis.github.io/data-wrangli...
cghlewis.github.io/data-wrangli...

need new IP as well:
"The WiRe" about trying to catch {stringr} Bell and tidyverse-ing up BaltimoRe
"The WiRe" about trying to catch {stringr} Bell and tidyverse-ing up BaltimoRe
August 21, 2025 at 8:47 PM
need new IP as well:
"The WiRe" about trying to catch {stringr} Bell and tidyverse-ing up BaltimoRe
"The WiRe" about trying to catch {stringr} Bell and tidyverse-ing up BaltimoRe