Didier Brassard
@didierbrassard.bsky.social
20 followers
53 following
20 posts
Postdoctoral research fellow.
💻 Nutritional epidemiology, aging, dietary assessment and causal inference (at least trying)
📍 Université de Montréal
Posts
Media
Videos
Starter Packs
Pinned





Reposted by Didier Brassard

Reposted by Didier Brassard



Reposted by Didier Brassard

Reposted by Didier Brassard


Reposted by Didier Brassard




Reposted by Didier Brassard

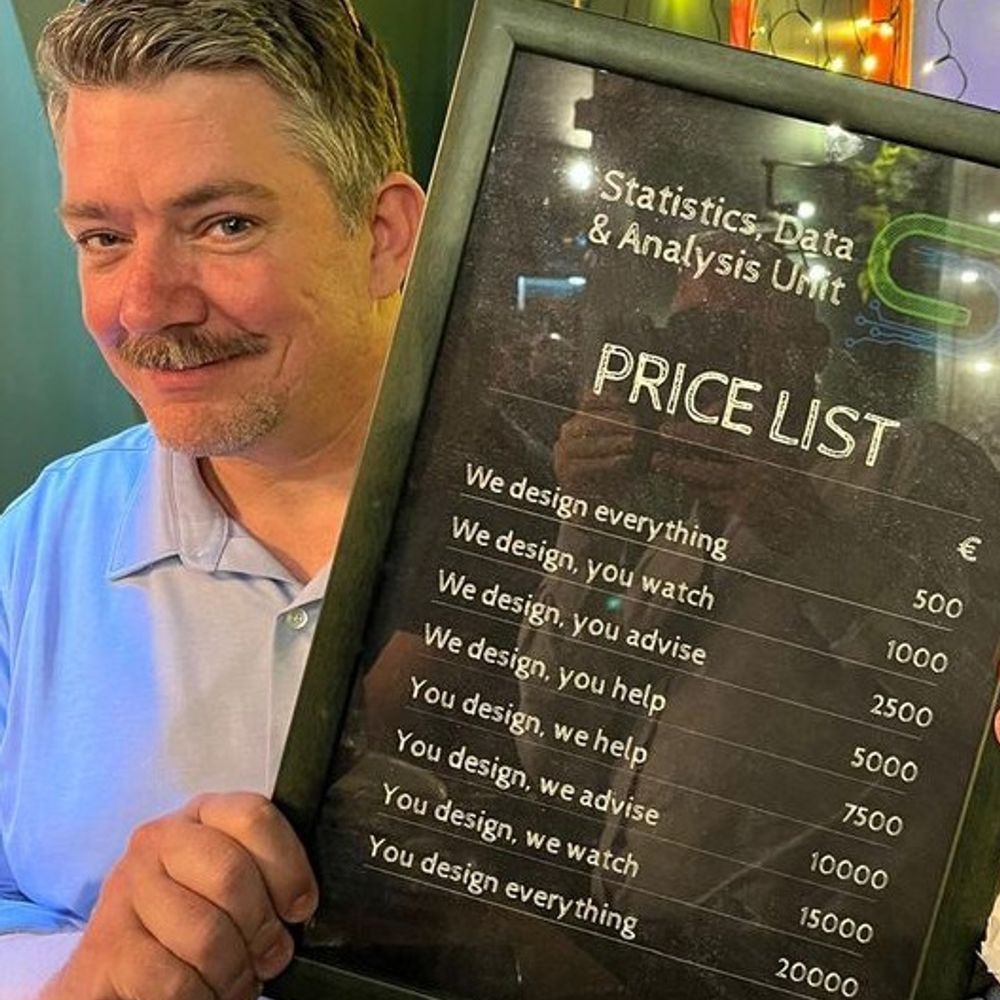


Reposted by Didier Brassard

Emily Riederer
@emilyriederer.bsky.social
· Jul 27
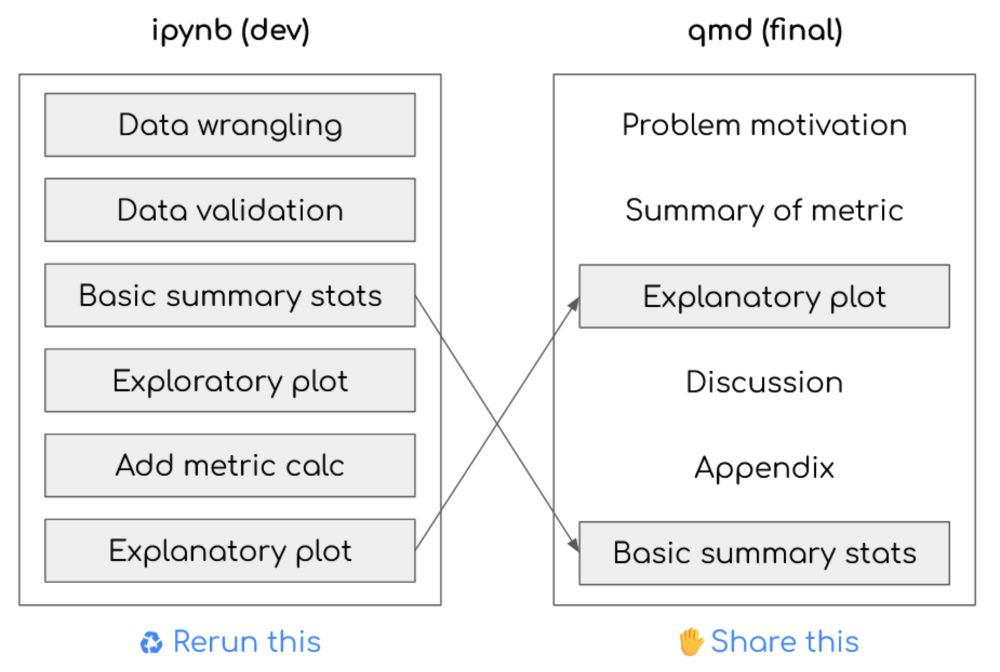
How Quarto embed fixes data science storytelling | Emily Riederer
Literate programming excels at capturing our stream of conscience. Our stream of conscience does not excel at explaining the impact of our work. Notebooks enable some of data scientists’ worst tendenc...
www.emilyriederer.com


Reposted by Didier Brassard

Ole Goltermann
@olegolt.bsky.social
· Jul 22

Concern About Predictive Performance of a Pain Sensitivity Biomarker
To the Editor Chowdhury et al1 evaluated a biomarker for pain sensitivity, combining peak alpha frequency and corticomotor excitability. The authors report outstanding performance (validation set area...
jamanetwork.com


Reposted by Didier Brassard

Jordan Nafa
@jordannafa.bsky.social
· Jul 15
Reposted by Didier Brassard

Reposted by Didier Brassard

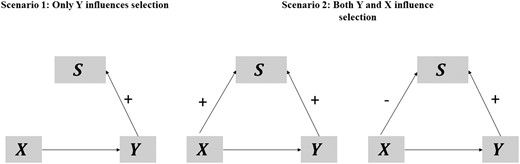




Reposted by Didier Brassard

