Chandan Singh
@csinva.bsky.social
650 followers
97 following
9 posts
Seeking superhuman explanations.
Senior researcher at Microsoft Research, PhD from UC Berkeley, https://csinva.io/
Posts
Media
Videos
Starter Packs
Reposted by Chandan Singh


Reposted by Chandan Singh

Alexander Huth
@alexanderhuth.bsky.social
· Aug 18

Reposted by Chandan Singh


Chandan Singh
@csinva.bsky.social
· Aug 14
Chandan Singh
@csinva.bsky.social
· Aug 14

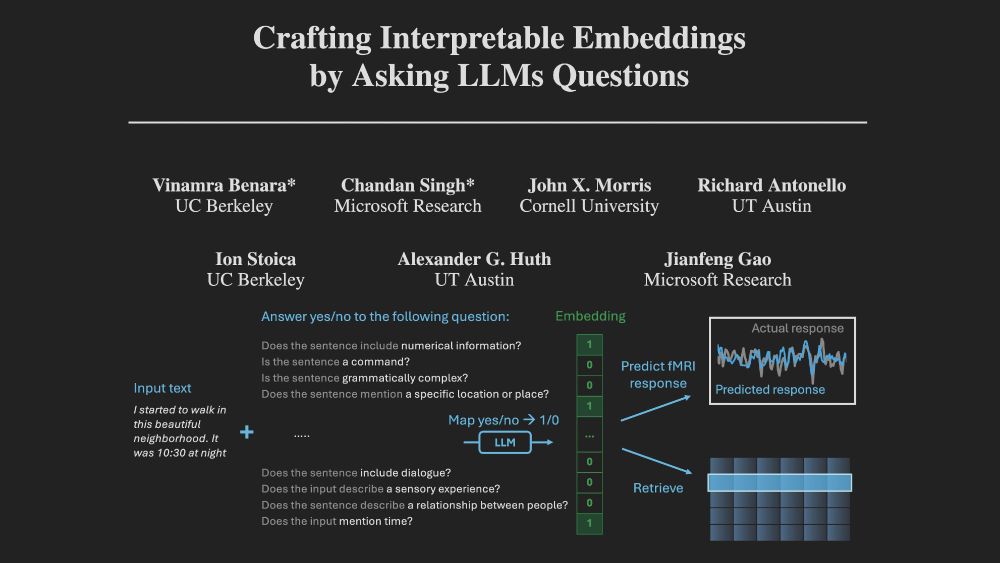
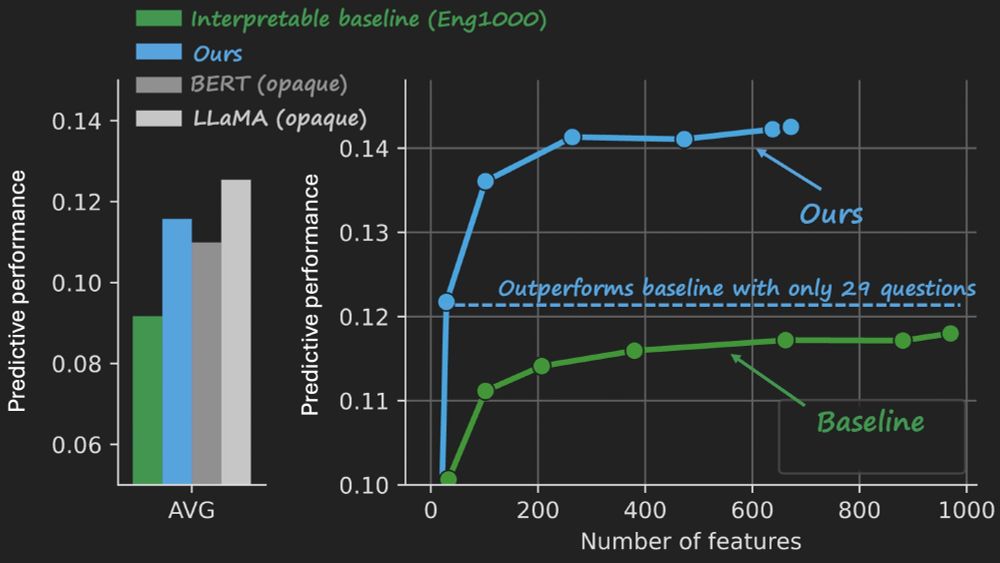

Reposted by Chandan Singh



Reposted by Chandan Singh
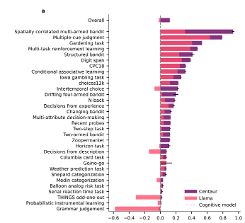
Reposted by Chandan Singh

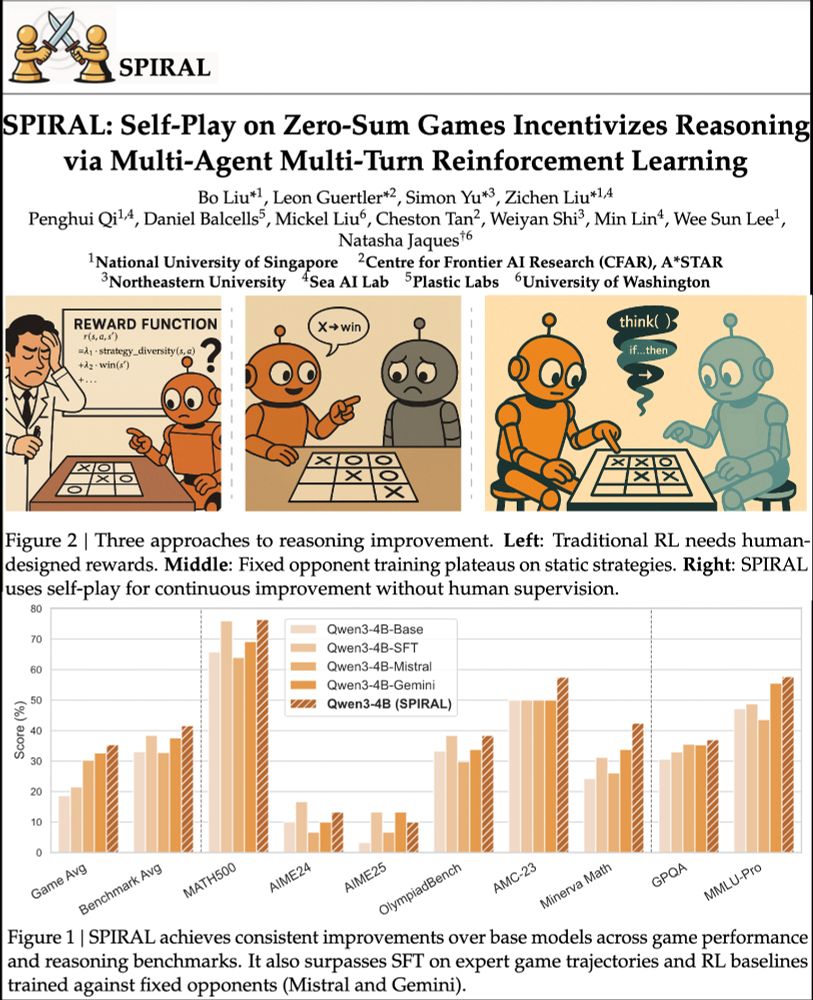
Reposted by Chandan Singh

Reposted by Chandan Singh

Martin Hebart
@martinhebart.bsky.social
· Jun 23
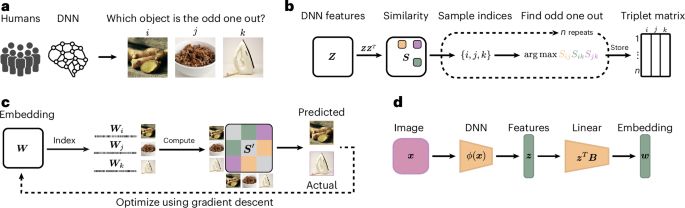
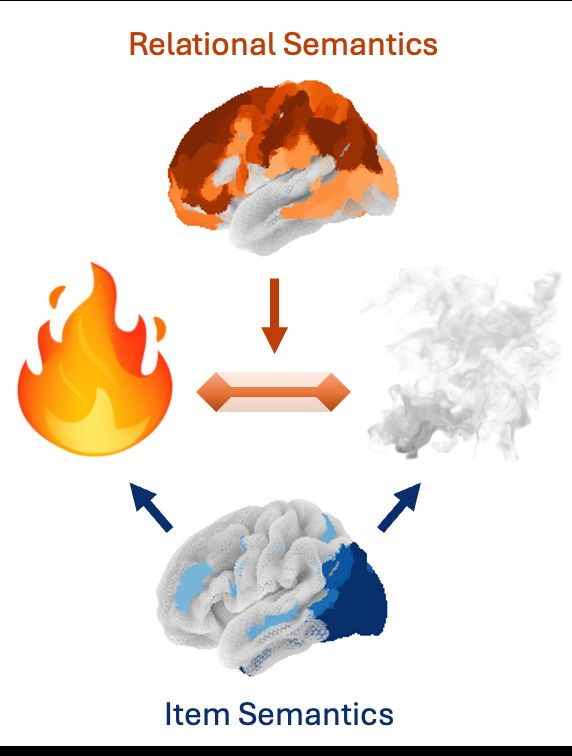
Dimensions underlying the representational alignment of deep neural networks with humans - Nature Machine Intelligence
An interpretability framework that compares how humans and deep neural networks process images has been presented. Their findings reveal that, unlike humans, deep neural networks focus more on visual ...
www.nature.com
Reposted by Chandan Singh

Reposted by Chandan Singh

Reposted by Chandan Singh


Reposted by Chandan Singh

Reposted by Chandan Singh

Erica Busch
@elbusch.bsky.social
· Apr 3

Accelerated learning of a noninvasive human brain-computer interface via manifold geometry
Brain-computer interfaces (BCIs) promise to restore and enhance a wide range of human capabilities. However, a barrier to the adoption of BCIs is how long it can take users to learn to control them. W...
doi.org
Reposted by Chandan Singh


Reposted by Chandan Singh

Nanthia Suthana
@suthanalab.bsky.social
· Mar 10
Human neural dynamics of real-world and imagined navigation - Nature Human Behaviour
Seeber et al. studied brain recordings from implanted electrodes in freely moving humans. Neural dynamics encoded actual and imagined routes similarly, demonstrating parallels between navigational, im...
www.nature.com
Reposted by Chandan Singh


Reposted by Chandan Singh


Reposted by Chandan Singh


Reposted by Chandan Singh

