



Max Kagan
@maxkagan.bsky.social
Postdoc at Columbia Business School studying partisan sorting at work.
https://www.maxkagan.com/
https://www.maxkagan.com/
@causalinf.bsky.social nails the experience of using Claude Code and how it is so different from what has come before. People want to know "how do I use the AI" and the answer is simple: "just talk to it!"

February 8, 2026 at 6:48 PM
@causalinf.bsky.social nails the experience of using Claude Code and how it is so different from what has come before. People want to know "how do I use the AI" and the answer is simple: "just talk to it!"
On the "does ideological moderation help candidates win debate?":
- candidates' ideology reflect strategic choices (endogeniety)
- perceptions of candidate ideology are related to candidate quality (endogeneity)
- favorable race dynamics attract higher-quality candidates (endogeneity)
🤔🤔🤔
- candidates' ideology reflect strategic choices (endogeniety)
- perceptions of candidate ideology are related to candidate quality (endogeneity)
- favorable race dynamics attract higher-quality candidates (endogeneity)
🤔🤔🤔
February 4, 2026 at 6:50 AM
On the "does ideological moderation help candidates win debate?":
- candidates' ideology reflect strategic choices (endogeniety)
- perceptions of candidate ideology are related to candidate quality (endogeneity)
- favorable race dynamics attract higher-quality candidates (endogeneity)
🤔🤔🤔
- candidates' ideology reflect strategic choices (endogeniety)
- perceptions of candidate ideology are related to candidate quality (endogeneity)
- favorable race dynamics attract higher-quality candidates (endogeneity)
🤔🤔🤔
Reposted by Max Kagan

🧵 New version of our paper (@bcegerod.bsky.social) is finally online: "How Many is Enough? Sample Size in Staggered Difference-in-Differences Designs"
We show that even well-identified DiD studies are often underpowered; sample sizes needed are surprisingly large
Paper: osf.io/preprints/os... 1/6
We show that even well-identified DiD studies are often underpowered; sample sizes needed are surprisingly large
Paper: osf.io/preprints/os... 1/6

February 3, 2026 at 2:46 PM
🧵 New version of our paper (@bcegerod.bsky.social) is finally online: "How Many is Enough? Sample Size in Staggered Difference-in-Differences Designs"
We show that even well-identified DiD studies are often underpowered; sample sizes needed are surprisingly large
Paper: osf.io/preprints/os... 1/6
We show that even well-identified DiD studies are often underpowered; sample sizes needed are surprisingly large
Paper: osf.io/preprints/os... 1/6
Reposted by Max Kagan

Things are grim. But in more frivolous news...
@jamesbrandecon.bsky.social and I have been chipping away at `dbreg`, a 📦 for running big regression models on database backends. For the right kinds of problems, the speed-ups are near magical.
Website: grantmcdermott.com/dbreg/
#rstats
[1/2]
@jamesbrandecon.bsky.social and I have been chipping away at `dbreg`, a 📦 for running big regression models on database backends. For the right kinds of problems, the speed-ups are near magical.
Website: grantmcdermott.com/dbreg/
#rstats
[1/2]
dbreg
grantmcdermott.com
January 26, 2026 at 4:57 PM
Things are grim. But in more frivolous news...
@jamesbrandecon.bsky.social and I have been chipping away at `dbreg`, a 📦 for running big regression models on database backends. For the right kinds of problems, the speed-ups are near magical.
Website: grantmcdermott.com/dbreg/
#rstats
[1/2]
@jamesbrandecon.bsky.social and I have been chipping away at `dbreg`, a 📦 for running big regression models on database backends. For the right kinds of problems, the speed-ups are near magical.
Website: grantmcdermott.com/dbreg/
#rstats
[1/2]
Reposted by Max Kagan

🎺 Call for proposals 🎺
1️⃣ replicate an existing experiment
2️⃣ run a novel experiment
on repdata.com
3️⃣ coauthor with Mary McGrath and me to meta-analyze the replications and existing studies
4️⃣ publish your study
details: alexandercoppock.com/replication_...
applications open Feb 1
please repost!
1️⃣ replicate an existing experiment
2️⃣ run a novel experiment
on repdata.com
3️⃣ coauthor with Mary McGrath and me to meta-analyze the replications and existing studies
4️⃣ publish your study
details: alexandercoppock.com/replication_...
applications open Feb 1
please repost!

January 27, 2026 at 10:16 PM
🎺 Call for proposals 🎺
1️⃣ replicate an existing experiment
2️⃣ run a novel experiment
on repdata.com
3️⃣ coauthor with Mary McGrath and me to meta-analyze the replications and existing studies
4️⃣ publish your study
details: alexandercoppock.com/replication_...
applications open Feb 1
please repost!
1️⃣ replicate an existing experiment
2️⃣ run a novel experiment
on repdata.com
3️⃣ coauthor with Mary McGrath and me to meta-analyze the replications and existing studies
4️⃣ publish your study
details: alexandercoppock.com/replication_...
applications open Feb 1
please repost!
SV needs to pick up Polanyi (more of a slog than James C. Scott, but worth it). AI will be disruptive but the idea that it will inescapably accelerate inequality only follows if you assume societal institutions are not themselves likely to be disrupted.
www.wsj.com/tech/ai/why-...
www.wsj.com/tech/ai/why-...

Why the Tech World Thinks the American Dream Is Dying
Silicon Valley fears this is the last chance to amass generational wealth before AI makes money worthless.
www.wsj.com
January 19, 2026 at 11:55 PM
SV needs to pick up Polanyi (more of a slog than James C. Scott, but worth it). AI will be disruptive but the idea that it will inescapably accelerate inequality only follows if you assume societal institutions are not themselves likely to be disrupted.
www.wsj.com/tech/ai/why-...
www.wsj.com/tech/ai/why-...
Reposted by Max Kagan

“These findings provide clear evidence that data collected on MTurk simply cannot be trusted.”

January 8, 2026 at 8:47 PM
“These findings provide clear evidence that data collected on MTurk simply cannot be trusted.”
Bookmarking this for the next time I someone cites Ansolobehere et al. 2003 to claim that FEC donation records reflect ideological consumption and are thus a good measure of ideology for corporate elites
www.nytimes.com/interactive/...
www.nytimes.com/interactive/...

Hundreds of Big Post-Election Donors Have Benefited From Trump’s Return to Office
Well into his second term, the president and his allies have continued aggressively raising money. Many donors have interests before his administration, The Times found.
www.nytimes.com
December 23, 2025 at 4:03 AM
Bookmarking this for the next time I someone cites Ansolobehere et al. 2003 to claim that FEC donation records reflect ideological consumption and are thus a good measure of ideology for corporate elites
www.nytimes.com/interactive/...
www.nytimes.com/interactive/...
Reposted by Max Kagan

Measuring the Ideology of Political Parties Worldwide
vrollet.github.io/files/Ideolo...
vrollet.github.io/files/Ideolo...

November 18, 2025 at 1:24 PM
Measuring the Ideology of Political Parties Worldwide
vrollet.github.io/files/Ideolo...
vrollet.github.io/files/Ideolo...
🎉 Tremendously excited to announce the release of VRscores—an open-source dataset for researchers and journalists interested in studying the political lean of different employers.
November 12, 2025 at 3:08 PM
🎉 Tremendously excited to announce the release of VRscores—an open-source dataset for researchers and journalists interested in studying the political lean of different employers.
Reposted by Max Kagan

Companies are hiring many more internal policy specialists than lobbyists; it is a much larger investment in politics and internal expertise
www.andrewbenjaminhall.com/HallSun25.pdf
www.andrewbenjaminhall.com/HallSun25.pdf

October 8, 2025 at 10:27 PM
Companies are hiring many more internal policy specialists than lobbyists; it is a much larger investment in politics and internal expertise
www.andrewbenjaminhall.com/HallSun25.pdf
www.andrewbenjaminhall.com/HallSun25.pdf
Reposted by Max Kagan

Proposal for how to fix family wise error rates.
For every uncorrected p value you must add an extra letter to the claim.
“Eating chocolate maaaaaaaaay be associated with lower rates of stroke”
For every uncorrected p value you must add an extra letter to the claim.
“Eating chocolate maaaaaaaaay be associated with lower rates of stroke”
September 16, 2025 at 6:55 PM
Proposal for how to fix family wise error rates.
For every uncorrected p value you must add an extra letter to the claim.
“Eating chocolate maaaaaaaaay be associated with lower rates of stroke”
For every uncorrected p value you must add an extra letter to the claim.
“Eating chocolate maaaaaaaaay be associated with lower rates of stroke”

Talks Between Adams and Trump Adviser Center on Saudi Ambassadorship
www.nytimes.com
September 5, 2025 at 2:40 PM
Excellent reference for those, like me, who can always benefit from a refresher on statistical power
September 4, 2025 at 1:28 AM
Excellent reference for those, like me, who can always benefit from a refresher on statistical power
Reposted by Max Kagan

📢 Thrilled to share our new article introducing CampaignView—a comprehensive open-source dataset of congressional candidate campaign bios and policy platforms (2018–2022). Paper + data here: campaignview.org & doi.org/10.7910/DVN/... 🧵1/4

July 10, 2025 at 5:00 PM
📢 Thrilled to share our new article introducing CampaignView—a comprehensive open-source dataset of congressional candidate campaign bios and policy platforms (2018–2022). Paper + data here: campaignview.org & doi.org/10.7910/DVN/... 🧵1/4
Wild times for those of us who study corporate sociopolitical activism
August 4, 2025 at 4:21 PM
Wild times for those of us who study corporate sociopolitical activism
Constitutional questions aside, it isn’t clear to me what the net partisan electoral effect would be? CA and NY would presumably lose representatives (and thus electors), but so would FL and TX?

NEW: GOP Rep. Marjorie Taylor Greene says she is introducing a bill requiring a new census "immediately upon enactment" & congressional redistricting using numbers that exclude non-U.S. citizens from census results that the 14th Amendment says must include the “whole number of persons in each state”

June 30, 2025 at 5:45 PM
Constitutional questions aside, it isn’t clear to me what the net partisan electoral effect would be? CA and NY would presumably lose representatives (and thus electors), but so would FL and TX?
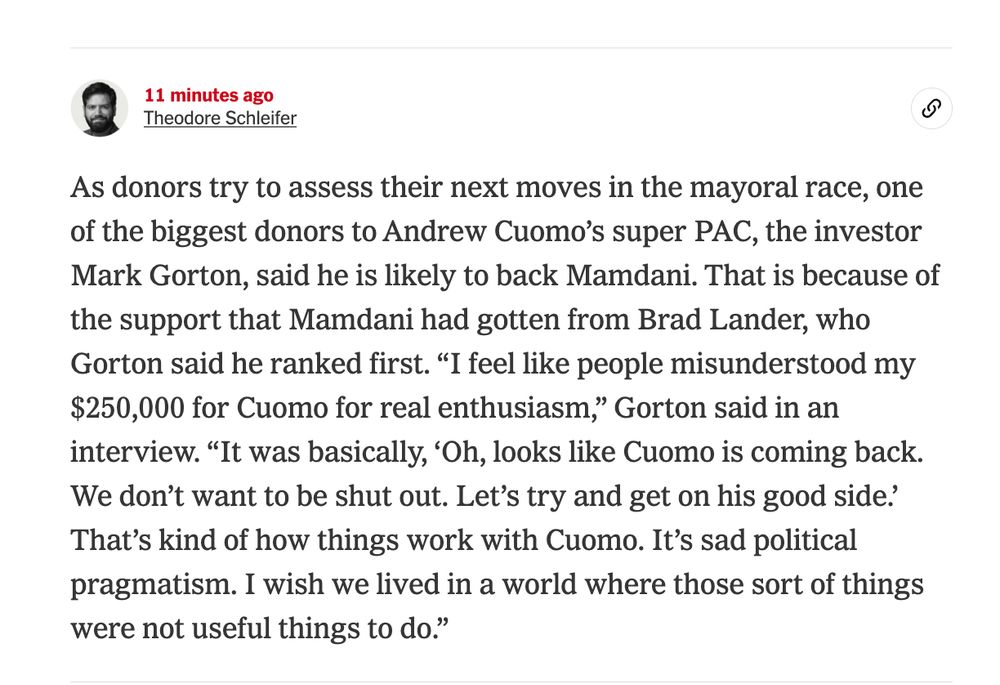
Much of my recent research has been thinking critically about whether it is always reasonable to use public campaign finance records as a good way to understand corporate executives' political ideology. So it is pretty striking to see someone "saying the quiet part out loud!"

Here's a fun thing that a top donor to Andrew Cuomo's super PAC just told me.
June 26, 2025 at 12:34 AM
Much of my recent research has been thinking critically about whether it is always reasonable to use public campaign finance records as a good way to understand corporate executives' political ideology. So it is pretty striking to see someone "saying the quiet part out loud!"
Reposted by Max Kagan

In the political literature this is known as donating for access. It’s very common. Campaign donations should be interpreted as strategic manifestations of political goals, not expressions of true preference.
Here's a fun thing that a top donor to Andrew Cuomo's super PAC just told me.
June 25, 2025 at 11:44 PM
In the political literature this is known as donating for access. It’s very common. Campaign donations should be interpreted as strategic manifestations of political goals, not expressions of true preference.
Reposted by Max Kagan

Going to #AOM2025 and working on #nonmarket strategy or know someone who is? Join our PDW on Research Frontiers in Nonmarket Strategy — now in its 8th year!
🗓️ Sat, July 26 | 11:00AM–1:30PM
📍 Bella Center, Auditorium 12
📝 Pre-register by ***July 1***: umdsurvey.umd.edu/jfe/form/SV_...
🗓️ Sat, July 26 | 11:00AM–1:30PM
📍 Bella Center, Auditorium 12
📝 Pre-register by ***July 1***: umdsurvey.umd.edu/jfe/form/SV_...
Qualtrics Survey | Qualtrics Experience Management
The most powerful, simple and trusted way to gather experience data. Start your journey to experience management and try a free account today.
umdsurvey.umd.edu
June 23, 2025 at 4:19 PM
Going to #AOM2025 and working on #nonmarket strategy or know someone who is? Join our PDW on Research Frontiers in Nonmarket Strategy — now in its 8th year!
🗓️ Sat, July 26 | 11:00AM–1:30PM
📍 Bella Center, Auditorium 12
📝 Pre-register by ***July 1***: umdsurvey.umd.edu/jfe/form/SV_...
🗓️ Sat, July 26 | 11:00AM–1:30PM
📍 Bella Center, Auditorium 12
📝 Pre-register by ***July 1***: umdsurvey.umd.edu/jfe/form/SV_...
Reposted by Max Kagan

Measuring and Modeling Neighborhoods
Measuring and Modeling Neighborhoods By Cory McCartan, New York University, Jacob R. Brown, Boston University and Kosuke Imai, Harvard University Granular geographic data present new opportunities to understand how neighborhoods are formed, and how they…
Measuring and Modeling Neighborhoods By Cory McCartan, New York University, Jacob R. Brown, Boston University and Kosuke Imai, Harvard University Granular geographic data present new opportunities to understand how neighborhoods are formed, and how they…

Measuring and Modeling Neighborhoods
Measuring and Modeling Neighborhoods By Cory McCartan, New York University, Jacob R. Brown, Boston University and Kosuke Imai, Harvard University Granular geographic data present new opportunities to understand how neighborhoods are formed, and how they influence politics. At the same time, the inherent subjectivity of neighborhoods creates methodological challenges in measuring and modeling them. We develop an open-source survey instrument that allows respondents to draw their neighborhoods on a map.
politicalsciencenow.com
June 12, 2025 at 2:00 PM
Measuring and Modeling Neighborhoods
Measuring and Modeling Neighborhoods By Cory McCartan, New York University, Jacob R. Brown, Boston University and Kosuke Imai, Harvard University Granular geographic data present new opportunities to understand how neighborhoods are formed, and how they…
Measuring and Modeling Neighborhoods By Cory McCartan, New York University, Jacob R. Brown, Boston University and Kosuke Imai, Harvard University Granular geographic data present new opportunities to understand how neighborhoods are formed, and how they…
Reposted by Max Kagan

📄 @fgilardi.bsky.social created this template for writing abstracts several years ago, and I’ve tried to follow Fabrizio‘s suggestions ever since.
PDF: fabriziogilardi.org/resources/pa...
PDF: fabriziogilardi.org/resources/pa...

June 5, 2025 at 1:46 PM
📄 @fgilardi.bsky.social created this template for writing abstracts several years ago, and I’ve tried to follow Fabrizio‘s suggestions ever since.
PDF: fabriziogilardi.org/resources/pa...
PDF: fabriziogilardi.org/resources/pa...
Reposted by Max Kagan

Americans who report paying “a lot of attention” to news (everyone on this platform) are (a) in the minority of voters and (b) very, very prone to assuming the other side of the aisle is all extremists. This is counterproductive to broader party efforts at persuasion. I have sources:
🧵
🧵
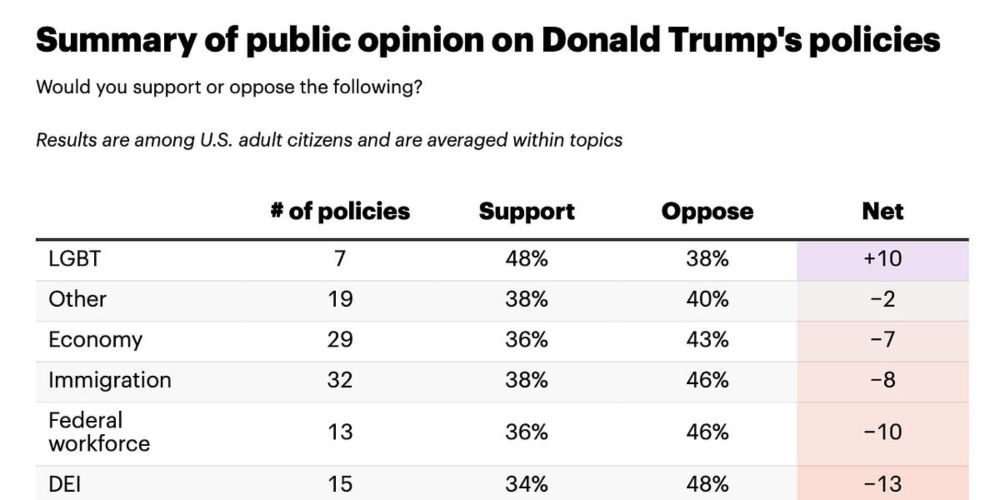
Not all Trump voters "voted for this"
Trump’s policy agenda is very unpopular, including with many of his supporters. To win the next election, Democrats need to welcome regretful Trump voters back onto their side
www.gelliottmorris.com
June 2, 2025 at 1:40 PM
Americans who report paying “a lot of attention” to news (everyone on this platform) are (a) in the minority of voters and (b) very, very prone to assuming the other side of the aisle is all extremists. This is counterproductive to broader party efforts at persuasion. I have sources:
🧵
🧵
Reposted by Max Kagan
Most people consume less than 1 hour of news per day (Pew). The result of this is that they are simply not or are ill/mis-informed, and do not have hard preferences on policy or parties. About 15-20% of voters can correctly identify positions as belonging to the left or right (Kinder and Kalmoe, 17)
June 2, 2025 at 1:40 PM
Most people consume less than 1 hour of news per day (Pew). The result of this is that they are simply not or are ill/mis-informed, and do not have hard preferences on policy or parties. About 15-20% of voters can correctly identify positions as belonging to the left or right (Kinder and Kalmoe, 17)
Some of us have been saying this for years.
May 15, 2025 at 5:23 PM
Some of us have been saying this for years.