by John Kane — Reposted by: Winston T. Lin

IMO, there are only 3 good reasons to do it. One of them needs to be true--otherwise, don't.
medium.com/the-quantast...


www.aeaweb.org/articles?id=...

Reposted by: Winston T. Lin, Magnus Johansson

#statssky #episky
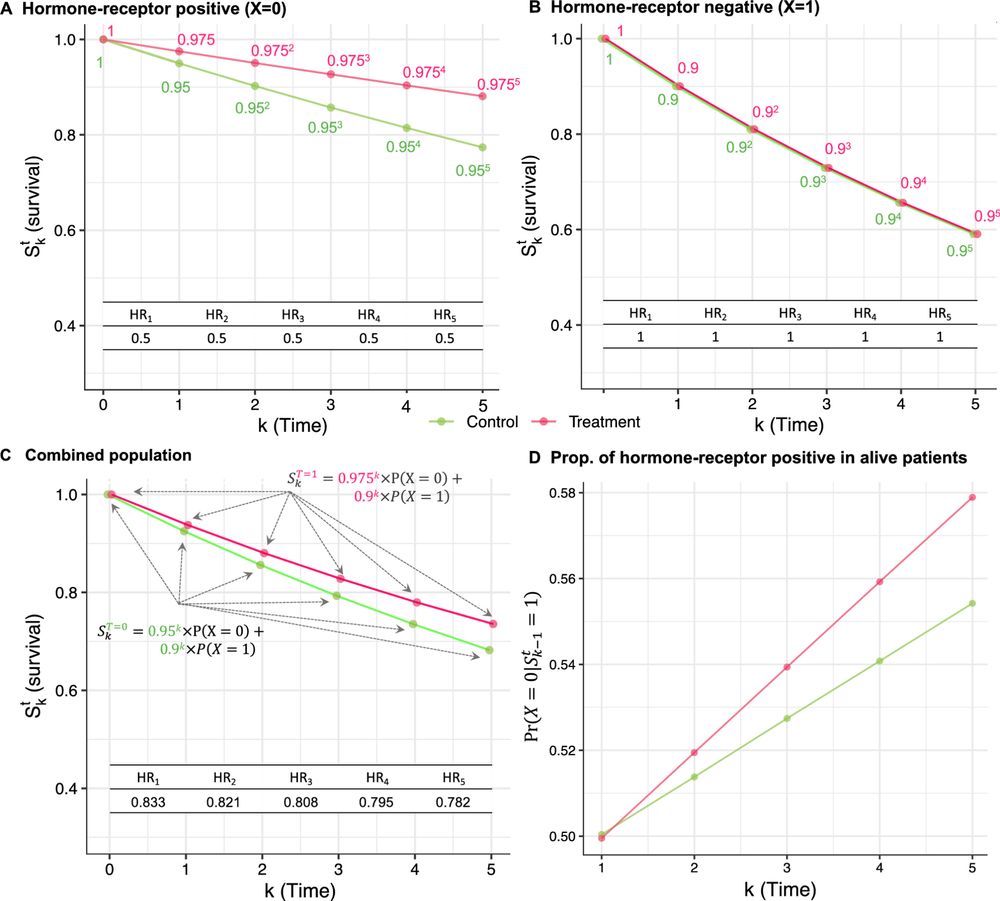
Reposted by: Winston T. Lin


Reposted by: Winston T. Lin


Reposted by: Winston T. Lin

Some notable changes:
-items on analysis populations, missing data methods, and sensitivity analyses
-reporting of non-adherence and concomitant care
-reporting of changes to any study methods, not just outcomes
-and lots of other things
www.bmj.com/content/389/...

Reposted by: Winston T. Lin



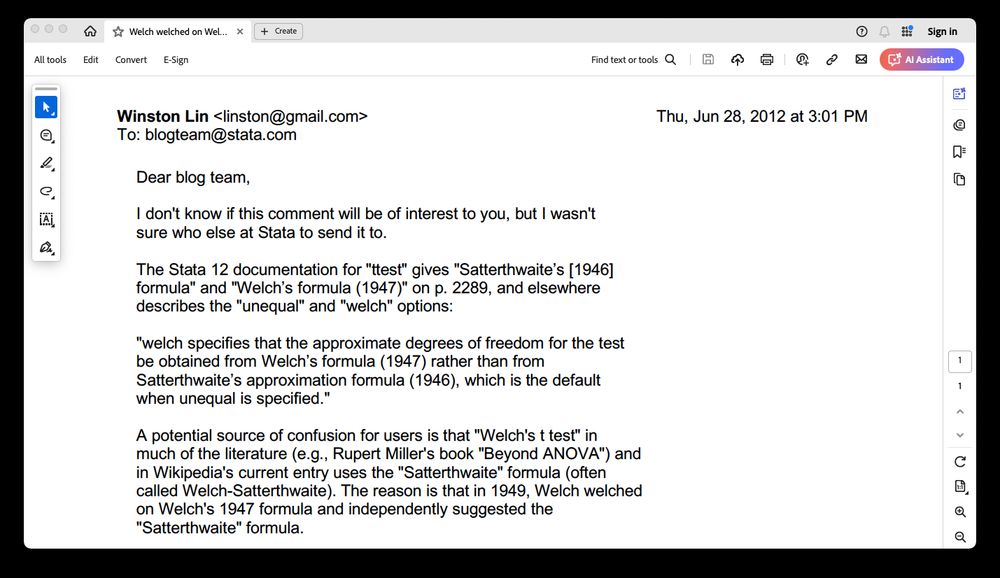
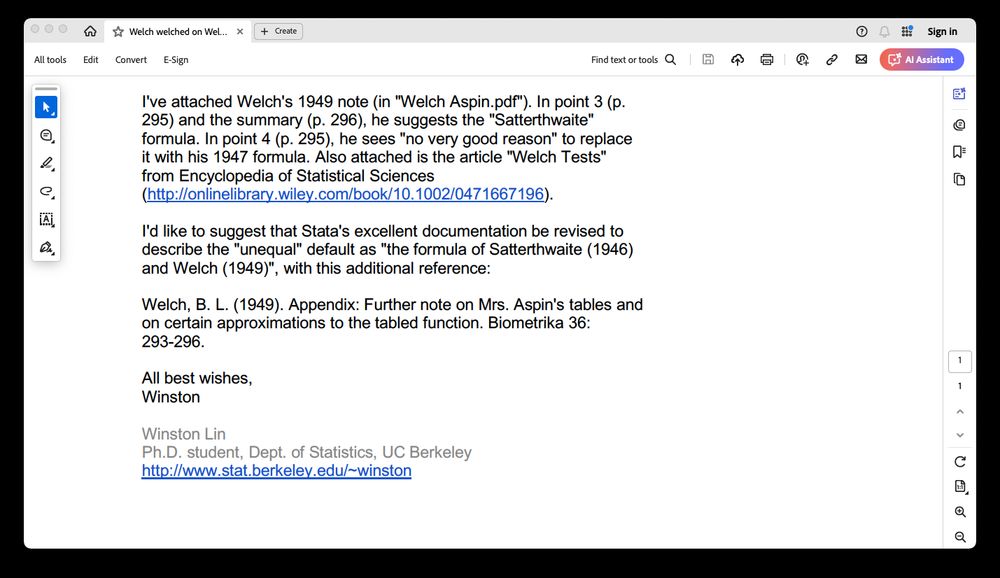

pubs.aeaweb.org/doi/pdf/10.1...

Reposted by: Winston T. Lin

Related paper #1
"Arguing for a Negligible Effect"
Journal: onlinelibrary.wiley....
PDF: www.carlislerainey.c...
Reposted by: Winston T. Lin
from Jack Fitzgerald (@jackfitzgerald.bsky.social)
Preprint: osf.io/preprints/met...
We know that "not significant" does not imply evidence for "no effect," but I still see papers make this leap.
Good to see more work making this point forcefully!

www.aeaweb.org/articles?id=...

doi.org/10.1002/sim....

Reposted by: Winston T. Lin



www.jstor.org/stable/2685805
doi.org/10.1214/ss/1...
by Ben H. Ansell — Reposted by: Winston T. Lin, Catherine C. Eckel, Matthias Doepke , and 10 more Winston T. Lin, Catherine C. Eckel, Matthias Doepke, Alberto Bisin, Jon H. Fiva, Dominic Nyhuis, Tayfun Sönmez, Michael A. Goldstein, Ioana Marinescu, Micaël Castanheira, Jonathan Heathcote, Mike Kestemont, Michael E. Rose

As a result, valuable debate happens in secret, and the resulting paper is an opaque compromise with anonymous co-authors called referees.
1/
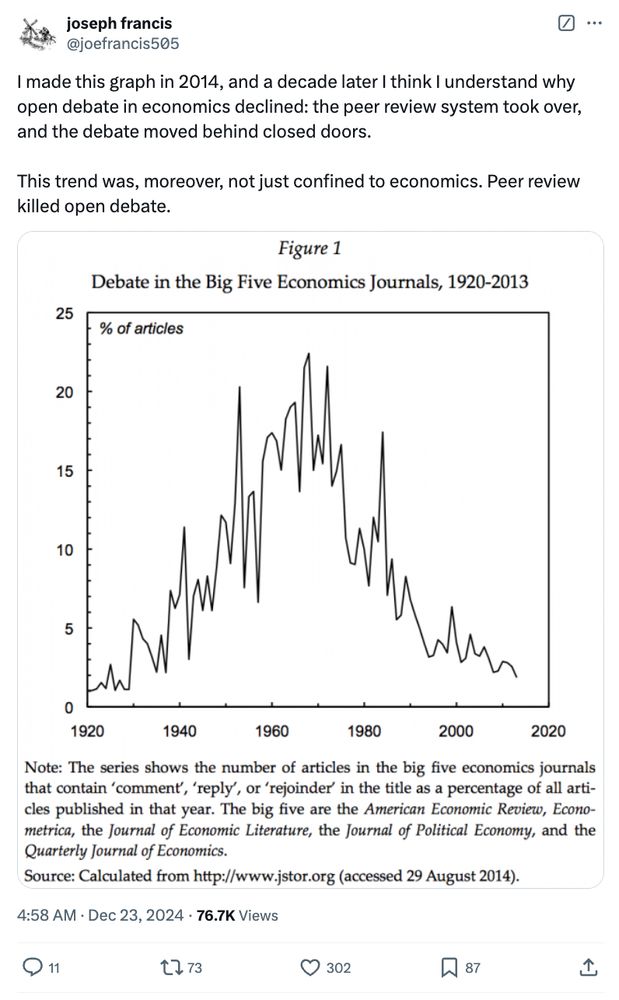
x.com/linstonwin/s...
Reposted by: Winston T. Lin